
For over two years the collective AMD vs Intel personal computer battle has been sitting on the edge of its seat. Back in 2014 when AMD first announced it was pursuing an all-new microarchitecture, old hands recalled the days when the battle between AMD and Intel was fun to be a part of, and users were happy that the competition led to innovation: not soon after, the Core microarchitecture became the dominant force in modern personal computing today. Through the various press release cycles from AMD stemming from that original Zen announcement, the industry is in a whipped frenzy waiting to see if AMD, through rehiring guru Jim Keller and laying the foundations of a wide and deep processor team for the next decade, can hold the incumbent to account. With AMD’s first use of a 14nm FinFET node on CPUs, today is the day Zen hits the shelves and benchmark results can be published: Game On!
[A side note for anyone reading this on March 2nd. Most of the review is done, bar an edit pass or two. Most of the results pages have graphs, but no text. Please have patience while we finish.]
As AnandTech moves into its 20th anniversary, it seems poignant to note that one of our first big review pieces that gained notoriety, back in 1997, was on a new AMD processor launch. Our style and testing regime since then has expanded and diversified through performance, gaming, microarchitecture, design, feature-set and debugging marketing strategy. (Fair play to Anand, he was only 14 years old back then…!). Our review for Ryzen aims to encompass many of the areas we feel pertinent to the scale of today’s launch.
An Interview with Dr Lisa Su, CEO of AMD
The Product Launch: A Small Stack of CPUs
Microarchitecture: Front-End, Back-End, micro-op cache, GloFo 14nm LP
Chipsets and Motherboards: AM4 and 300-series
Stock Coolers and Memory: Wraith and DDR4
Benchmarking Performance: Our New 2017 CPU Benchmark Suite
Conclusions
Before the official launch, AMD held a traditional ‘Tech Day’ for key press and analysts in the past week over in San Francisco. The goal of the Tech Day was to explain Zen to the press, before the press explain it to everyone else. AMD likes doing Tech Days, with recent events in memory covering Polaris and Carrizo, and I don’t blame them: alongside the usual slide presentations recapping what is already known or ISSCC/Hot Chips papers, we also get a chance to sit down with the VPs and C-Level executives as well as the key senior engineers involved in the products. Some of the information in this piece we would have published before: AMD’s machine of tickle-out information means that we know a good deal behind the design already, but the Tech Day helps us ask those final questions, along with the official launch details.
A Brief Backstory and Context
The world of main system processors, or CPUs in this case, is governed at a high level by architecture (x86, ARM), microarchitecture (how the silicon is laid out), and process node (such as 28HPM and 16FF+ from TSMC, or 14LP from GloFo). Beyond these we have issues of die area, power consumption, transistor leakage, cost, compatibility, dark silicon, frequency, supported features and time to market.
Over the past decade, both AMD and their main competitor Intel have been competing for the desktop and server computer markets with processors based on the x86 CPU architecture. Intel moved to its leading Core microarchitecture on 32nm around 2010, and is now currently in its seventh generation of it at 14nm, with each generation implementing various front-end/back-end changes and design adjustments to caches and/or modularity (it’s actually a lot more complex than this). By comparison, AMD is running its fourth/fifth generation of Bulldozer microarchitecture, split between its high-end CPUs (running an older 2nd Generation on 32nm), its mainstream graphics focused APUs (running 4th/5th Generation on 28nm), and laptop-based APUs (on 5th Generation).
| High-Performance and Mainstream x86 Microarchitectures |
||||
| AMD | Year | Intel | ||
| Zen | 14FF | 2017 | ? | |
| Excavator v2 | GF28A | 2016 | 14+FF | Kaby Lake |
| Excavator | GF28A | 2015 | 14FF | Skylake |
| Steamroller | 28SHP | 2014 | 14FF | Broadwell |
| – | – | 2013 | 22FF | Haswell |
| Piledriver | 32 SOI | 2012 | 22FF | Ivy Bridge |
| Bulldozer | 32nm | 2011 | 32nm | Sandy Bridge |
| – | – | 2010 | 32mm | Westmere |
| K10 | 45nm | Other | 45nm | Nehalem |
AMD’s Bulldozer-based design was an ambitious goal: typically a processor core will have a single instruction entry point leading to a decode then dispatch to separate integer or floating point schedulers. Bulldozer doubled the integer scheduler and throughput capabilities, and allowed the module to accept two threads of instructions – this meant that integer heavy workloads could perform well, other bottlenecks notwithstanding. The perception was that most OS-based workloads are invariably integer/whole number based, such as loop iterations or true/false Boolean comparisons or predicates. Unfortunately the design ended up with a couple of key issues: OS-based workloads ended up getting more floating-point heavy, traditional OSes didn’t understand how to dispatch work given a dual-thread module leading to overloaded modules (this was fixed with an update), general throughput of a single thread was a small (if any) upgrade over the previous microarchitecture design, and power consumption was high. A number of leading analysts pointed to design philosophies in the Bulldozer design, such as a write-through L1 cache and a shared L2 cache within a module lead to higher latencies and increased power consumption. A good chunk of the deficit to the competition was the lack of a micro-op cache that can help bypass instruction decode power and latency, as well as a process node disadvantage and the incumbent’s strong memory pre-fetch/branch prediction capabilities.
The latest generation of Bulldozer, using ‘Excavator’ cores under the Carrizo name for the chip as a whole, is actually quite a large jump from the original Bulldozer design. We have had extensive reviews of Carrizo for laptops, as well as a review of the sole Carrizo-based desktop CPU, and the final variant performed much better for a Bulldozer design than expected. The fundamental base philosophy was unchanged, however the use of new GPUs, a new metal stack in the silicon design, new monitoring technology, new threading/dispatch algorithms and new internal analysis techniques led to a lower power, higher performance version. This was at the expense of super high-end performance above35W, and so the chip was engineered to focus at more mainstream prices, but many of the technologies helped pave the way for the new Zen floorplan.
Zen is AMD’s new microarchitecture based on x86. Building a new base microarchitecture is not easy – it typically means a large paradigm shift in the way of thinking between the old design and new design in key areas. In recent years, Intel alternates key microarchitecture changes between two separate CPU design teams in the US and Israel. For Zen, AMD made strides to build a team suitable to return to the high-end. Perhaps the most prominent key hire was CPU Architect and all-around praised design guru Jim Keller. Jim has a prominent history in chip design, starting with the likes of Freescale, to developing chips for AMD when they fighting tooth and nail with Intel in the early 2000s, then moving on to Apple to work on the A5/A6 designs. AMD were able to re-hire Jim and put a fire in his belly with the phrase: ‘Make a new high-performance x86 CPU’ (not in those exact simple words…. I hope).

From left to right: Mark Papermaster (CTO AMD), Dr Lisa Su (CEO AMD),
Simon Segars (CEO ARM) and Jim Keller (former AMD, now Tesla)
Jim’s goal was to build the team and lay the groundwork for the new microarchitecture, which for the long-term will revolve around AMD Processor Architect Michael (Mike) Clark. Former Intel engineer Sam Naffziger, who was already working with AMD when the Zen team was put together, worked in tandem with the Carrizo and Zen teams on building internal metrics to assist with power as well. Mark Papermaster, CTO, has stated that over 300 dedicated engineers and two million man-hours have been put into Zen since its inception.
As mentioned, the goal was to lay down a framework. Jim Keller spent three years at AMD on Zen, before leaving to take a position under Elon Musk at Tesla. When we reported that Jim had left AMD, a number of people in the industry seemed confused: Zen wasn’t due for another year at best, so why had he left? The answers we had from AMD were simple – Jim and others had built the team, and laid the groundwork for Zen. With all the major building blocks in place, and simulations showing good results, all that was needed was fine tuning. Fine tuning is more complex than it sounds: getting caches to behave properly, moving data around the fabric at higher speeds, getting the desired memory and latency performance, getting power under control, working with Microsoft to ensure OS compatibility, and working with the semiconductor fabs (in this case, GlobalFoundries) to improve yields. None of this is typically influenced by the man at the top, so Jim’s job was done.
This means that in the past year or so, AMD has been working on that fine tuning. This is why we’ve slowly seen more and more information coming out of AMD regarding microarchitecture and new features as the fine-tuning slots into place. All this culminates in Ryzen, the official name for today’s launch.
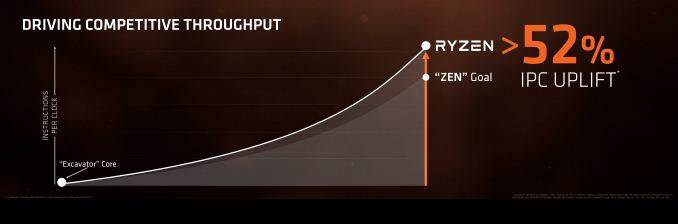
Along with the new microarchitecture, Zen is the first CPU from AMD to be launched on GlobalFoundries’ 14nm process, which is semi-licenced from Samsung. At a base overview, the process should offer 30% better efficiency over the 28nm HKMG (high-k metal gate) process used at TSMC for previous…





