
Using algorithms partially modeled on the human brain, researchers from the Massachusetts Institute of Technology have enabled computers to predict the immediate future by examining a photograph.
A program created at MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL) essentially watched 2 million online videos and observed how different types of scenes typically progress: people walk across golf courses, waves crash on the shore, and so on. Now, when it sees a new still image, it can generate a short video clip (roughly 1.5 seconds long) showing its vision of the immediate future.
Related: How Scientists Confirmed One of Einstein’s Controversial Theories
“It’s a system that tries to learn what are plausible videos — what are plausible motions you might see,” says Carl Vondrick, a graduate student at CSAIL and lead author on a related research paper to be presented this month at the Neural Information Processing Systems conference in Barcelona. The team aims to generate longer videos with more complex scenes in the future.
But Vondrick says applications could one day go beyond turning photos into computer-generated GIFs. The system’s ability to predict normal behavior could help spot unusual happenings in security footage or improve the reliability of self-driving cars, he says.
If the system spots something unusual, like an animal of a type it hasn’t seen before running into the road, Vondrick explains that the vehicle “can detect that and say, ‘Okay, I’ve never seen this situation before — I can stop and let the driver take over,’ for example.”

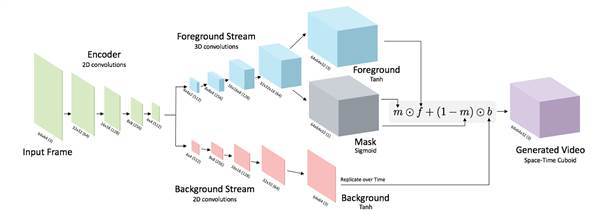
To create the program, the MIT team relied on a scientific technique called deep learning that’s become central to modern artificial intelligence research. It’s the approach that lets digital assistants like Apple’s Siri and Amazon’s Alexa understand what users want, and that drives image search and facial recognition advancements at Facebook and Google.
Experts say deep learning, which uses mathematical structures called neural networks to pull patterns from massive sets of data, could soon let computers make diagnoses from medical images, detect bank fraud, predict customer order patterns, and operate vehicles at least as well as people.
“Deep neural networks are performing better than humans on all kinds of significant problems, like image recognition, for example,” says Chris Nicholson, CEO of San Francisco startup Skymind, which develops deep learning software and offers consulting. “Without them, I think self-driving cars would be a danger on the roads, but with them, self-driving cars are safer than human drivers.”
Related: How the Tech Industry is Tackling the Cancer Moonshot
Neural networks take low-level inputs, like the pixels of an image or snippets of audio, and run them through a series of virtual layers, which assign relative weights to each individual piece of data in interpreting the input. The “deep” in deep learning refers to using tall stacks of these layers to collectively uncover more complex patterns in the data, expanding its understanding from pixels to basic shapes to features like stop signs and brake lights. To train the networks, programmers repeatedly test them on large sets of data, automatically tweaking the weights so the network makes fewer and fewer mistakes over time.
While research into neural networks, loosely based on the human brain, dates back decades, progress has been particularly remarkable in roughly the past ten years, Nicholson says. A 2006 set of papers by renowned computer scientist Geoffrey Hinton, who now divides his time between Google and the University of Toronto, helped pave the way for deep learning’s rapid development.


In 2012, a team including Hinton was the first to use deep learning to win a prestigious computer science competition called the ImageNet Large Scale Visual Recognition Challenge. The team’s program beat rivals by a wide margin at classifying objects in photographs into categories, performing with a 15.3 percent error rate compared to a 26.2 percent rate for the second-place entry.
This year, a Google-designed computer trained by deep learning defeated one of the world’s top Go players, a feat many experts of the ancient Asian board game had previously thought could be decades away. The system, called AlphaGo, learned in part by playing millions of simulated games against itself. While human chess players have long been bested by digital rivals, many experts had thought Go — which has significantly more sequences of valid moves — could be harder for computers to grasp.
In early November, a group from the University of Oxford unveiled a deep learning-based lipreading system that can outperform human experts. And this week, a team including researchers from Google published a paper in the Journal of the American Medical Association showing that deep learning could spot diabetic retinopathy roughly as well as trained ophthalmologists. That eye condition can cause blindness in people with diabetes, especially if they don’t have access to testing and treatment.
Related: Is Perfecting Artificial Intelligence This Generations Space Race?
“A lot of people don’t have access to a specialist who can access these [diagnostic] films, especially in underserved populations where the incidence of diabetes is going up and the number of eyecare professionals is flat,” says Dr. Lily Peng, a product manager at Google and lead author on the paper.
Like many of deep learning’s successes, the retinopathy research relied on a large set of training data, including roughly 128,000 images already classified by ophthalmologists. Deep learning is fundamentally a technique for the internet age, requiring datasets that only a few years ago would have been too big to even fit on a hard drive.
“It’s not as useful in cases where there’s not much data available,” Vondrick says. “If it’s very difficult to acquire data, then deep learning may not get you as far.”


Computers need a lot more examples than humans do to learn the same skills. Recent editions of the ImageNet challenge, which has added more sophisticated object recognition and scene analysis challenges as algorithms have grown more sophisticated, included hundreds of gigabytes of training data — orders of magnitude larger than a CD or DVD. Developers at Google train new algorithms from the company’s sweeping archive of search results and clicks, and companies racing to build self-driving vehicles collect vast amounts of sensor readings from heavily instrumented, human-driven cars.
…




