
02:28PM EDT – Welcome to Hot Chips! This is the annual convention all concerning the newest, best, and upcoming large silicon that will get us all excited. Stay tuned throughout Monday and Tuesday for our common AnandTech Live Blogs.
02:30PM EDT – Start right here in a pair minutes
02:30PM EDT – Friend of AT, David Kanter, is chair for this session
02:32PM EDT – ‘ML just isn’t the one sport on the town’
02:33PM EDT – First speak is CO-founder, CTO, Graphcore, Simon Knowles. Colossus MK2

02:34PM EDT – Designed for AI
02:34PM EDT – New structural sort of processor – the IPU

02:34PM EDT – ‘Why do we want new silicon for AI’
02:35PM EDT – Embracing graph knowledge by AI

02:36PM EDT – Classic scaling has ended
02:36PM EDT – Creating {hardware} to unravel graphs
02:37PM EDT – Control program can management the graph compute in one of the simplest ways to run on specialised {hardware}
02:37PM EDT – Hardware abstraction – tiles with processors and reminiscence with a IO interconnect
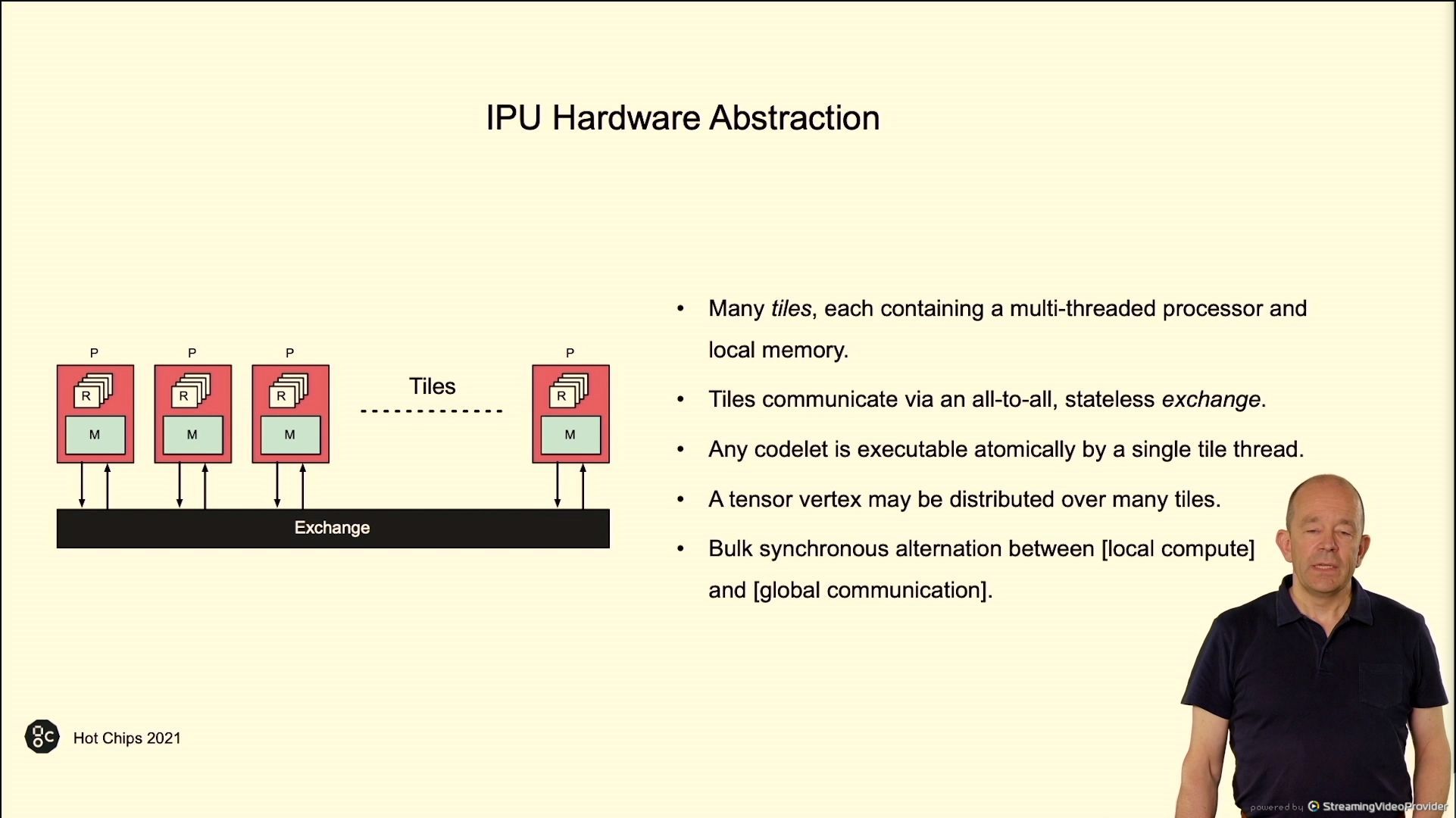
02:37PM EDT – bulk synchronous parallel compute
02:38PM EDT – thread fences for communication

02:38PM EDT – ‘document for actual transistors on a chip’
02:38PM EDT – This chip has extra transistors on it than every other N7 chip from TSMC
02:38PM EDT – inside one reticle
02:39PM EDT – 896 MiB of SRAM on N7

02:40PM EDT – four IPUs in a 1U
02:40PM EDT – Lightweight proxy host
02:41PM EDT – 1.2 Tb/s off-chassis IO
02:41PM EDT – 800-1200 W typical, 1500W peak
02:41PM EDT – Can use Pytorch, tensorflow, ONNX, however personal Poplar software program stack is most popular
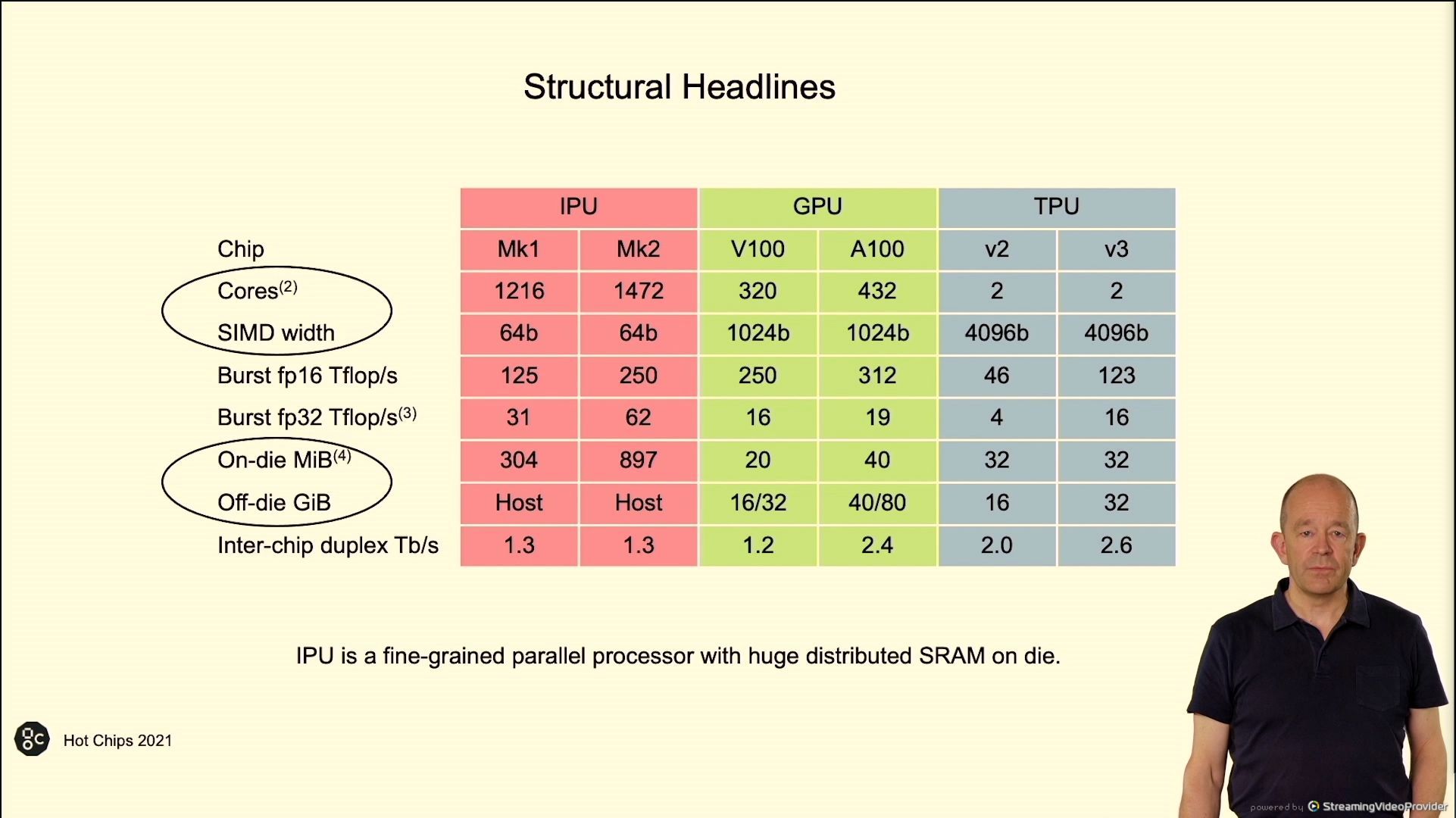
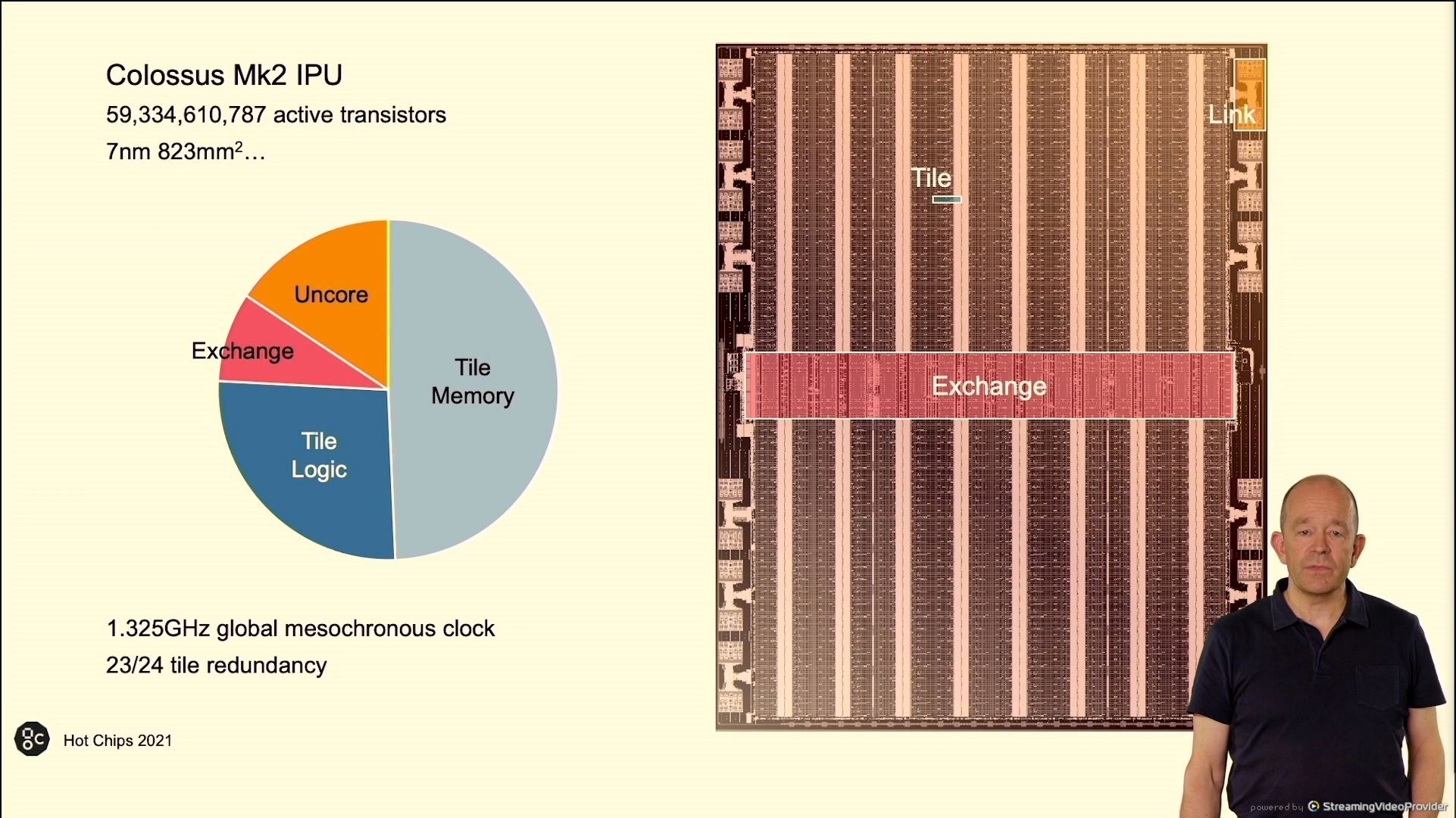
02:43PM EDT – Half the die is reminiscence
02:43PM EDT – 24 tiles, 23 are used to provide redundancy
02:43PM EDT – 25 GHz international clock
02:43PM EDT – 823 mm2, TSMC N7
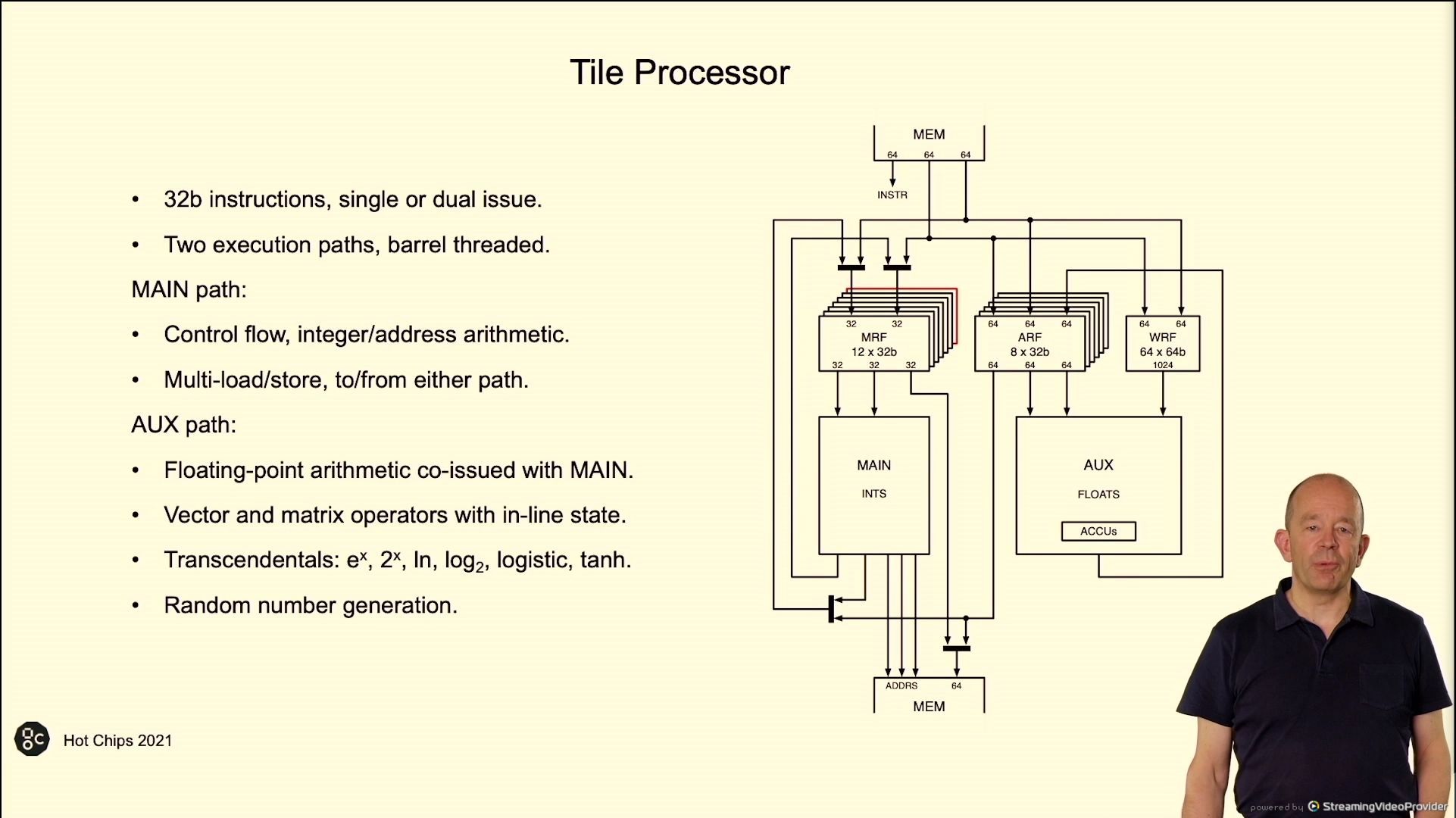
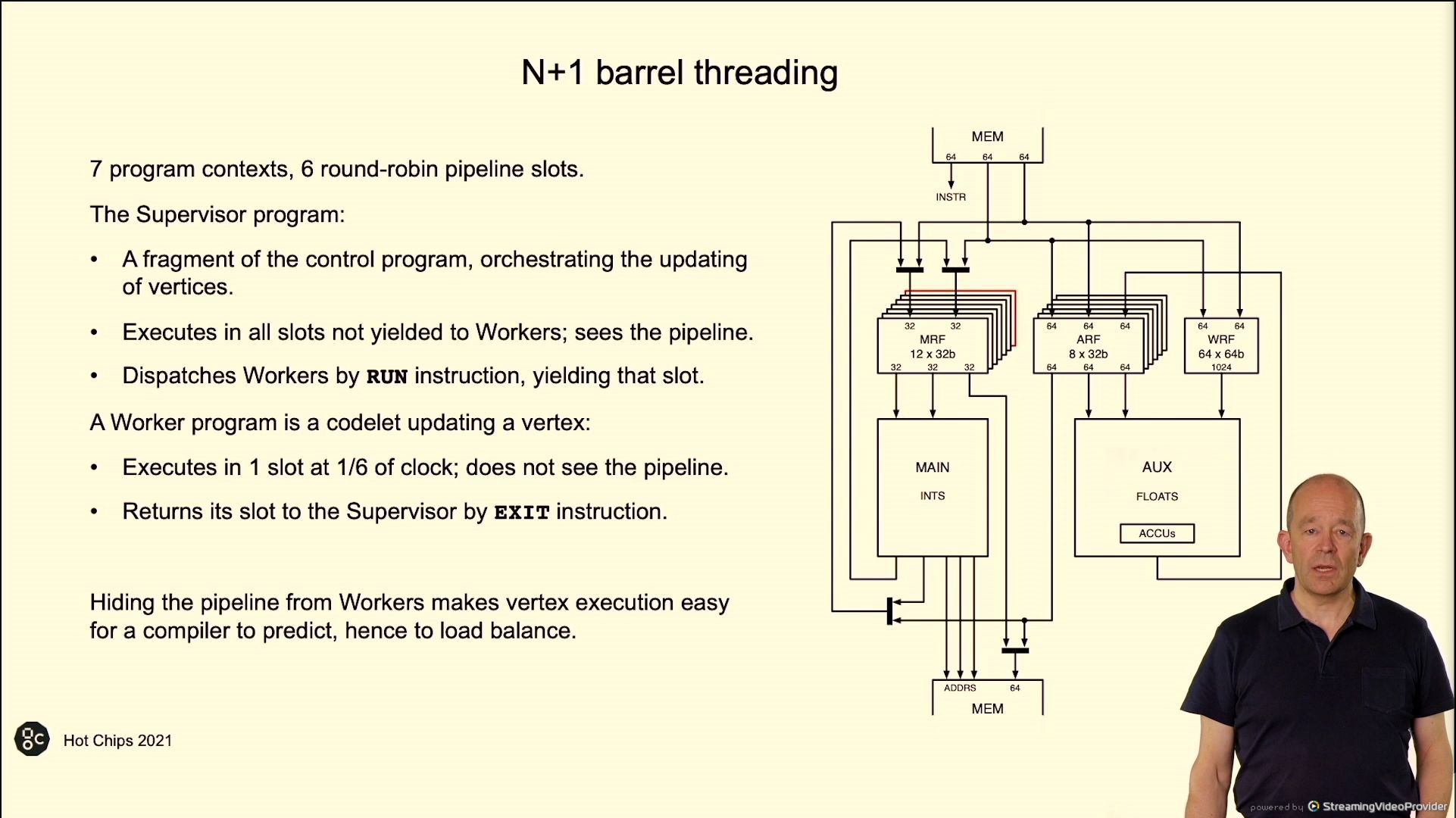
02:44PM EDT – 32 bit directions, single or twin concern
02:44PM EDT – 6 execution threads, launch employee threads to do the heavy lifting
02:45PM EDT – Aim for load balancing

02:45PM EDT – 1.325 GHz* international clock
02:46PM EDT – 47 TB/s data-side SRAM entry
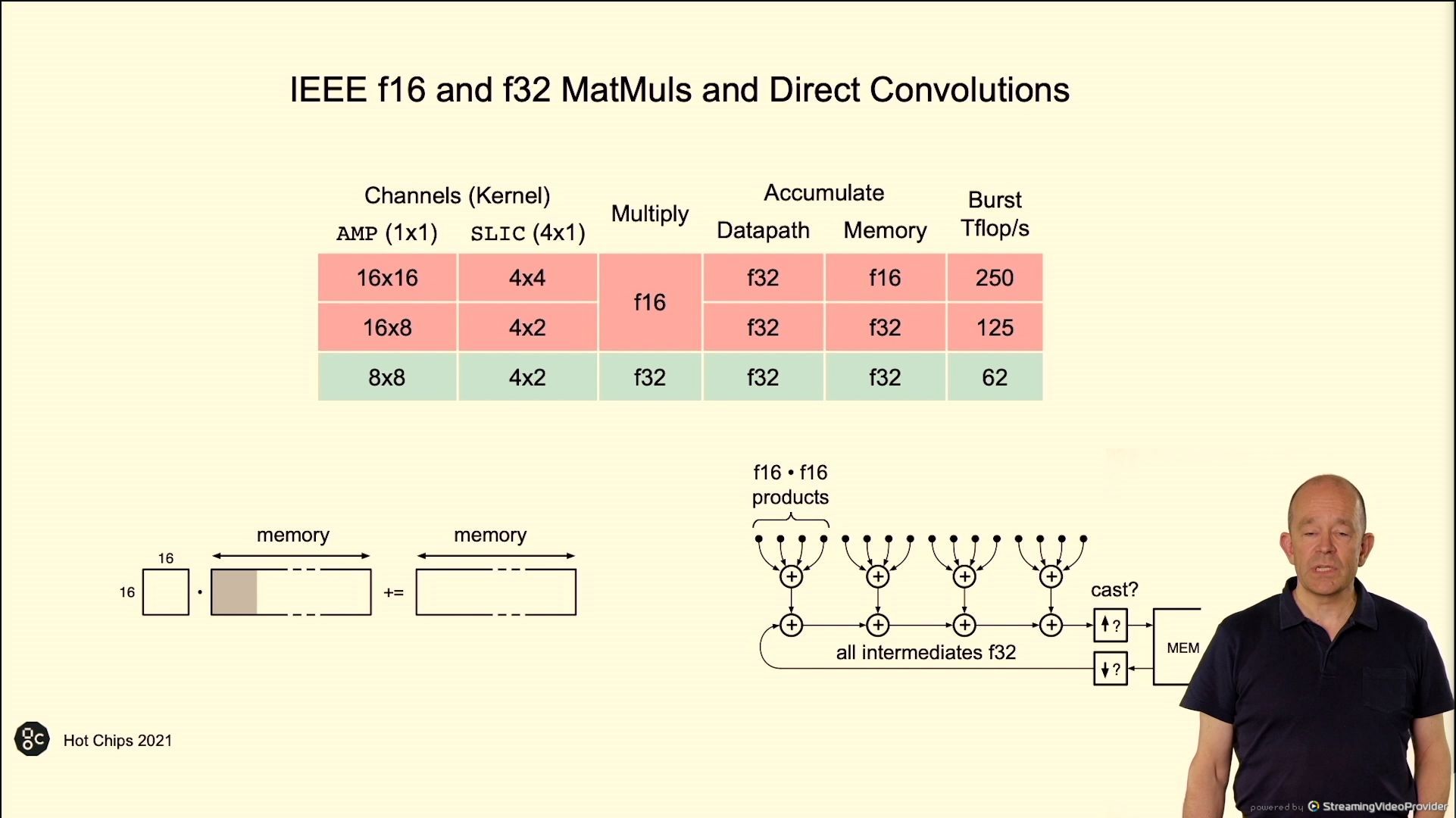
02:46PM EDT – FP16 and FP32 MatMul and convolutions
02:47PM EDT – TPU depends an excessive amount of on massive matrices for top efficiency

02:48PM EDT – Each tile can generate 128 random bits per cycle
02:48PM EDT – can spherical down stochastically
02:48PM EDT – at full velocity
02:48PM EDT – Avoid FP32 knowledge with stochastic rounding. Helps reduce rounding and power use
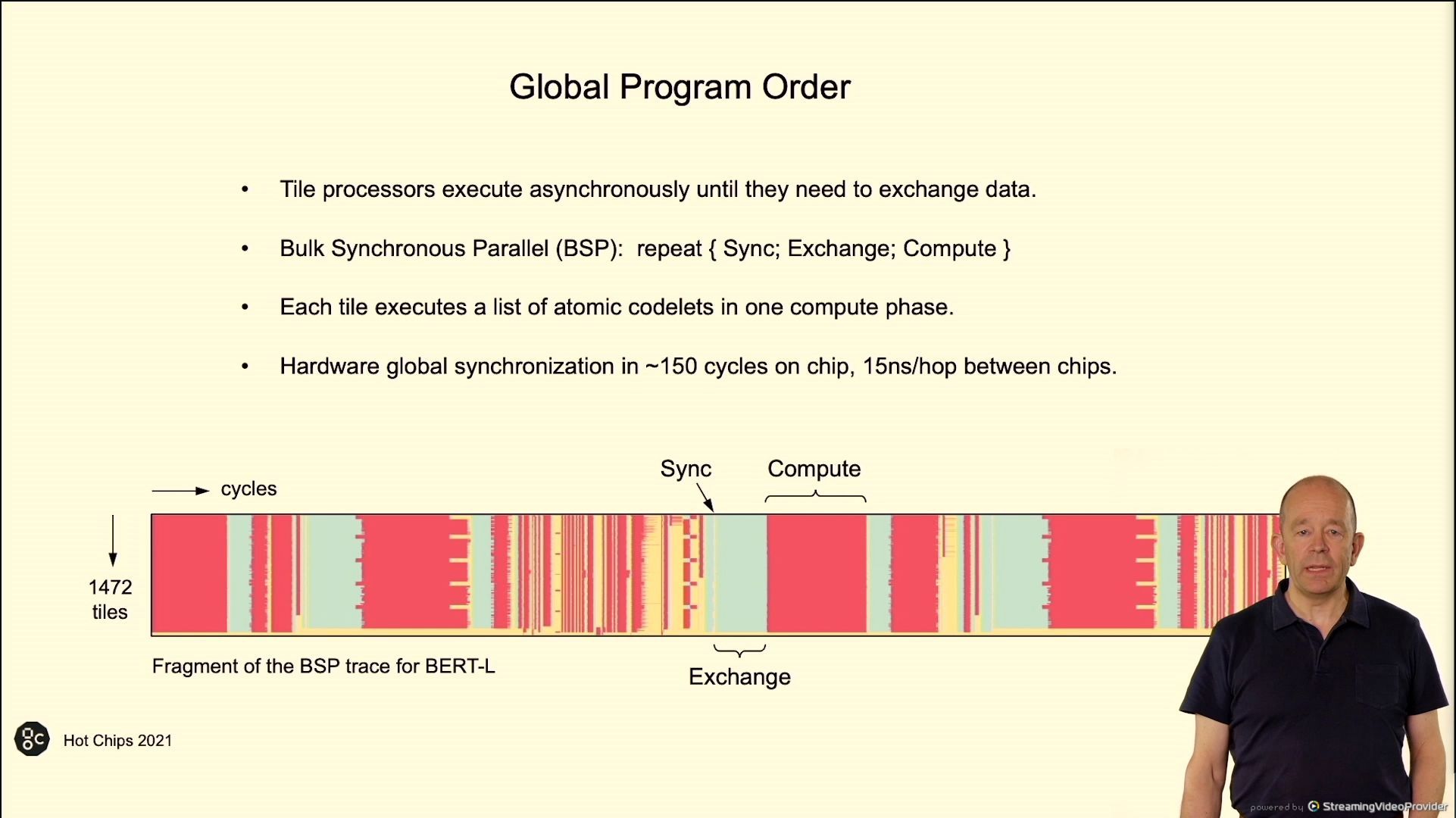
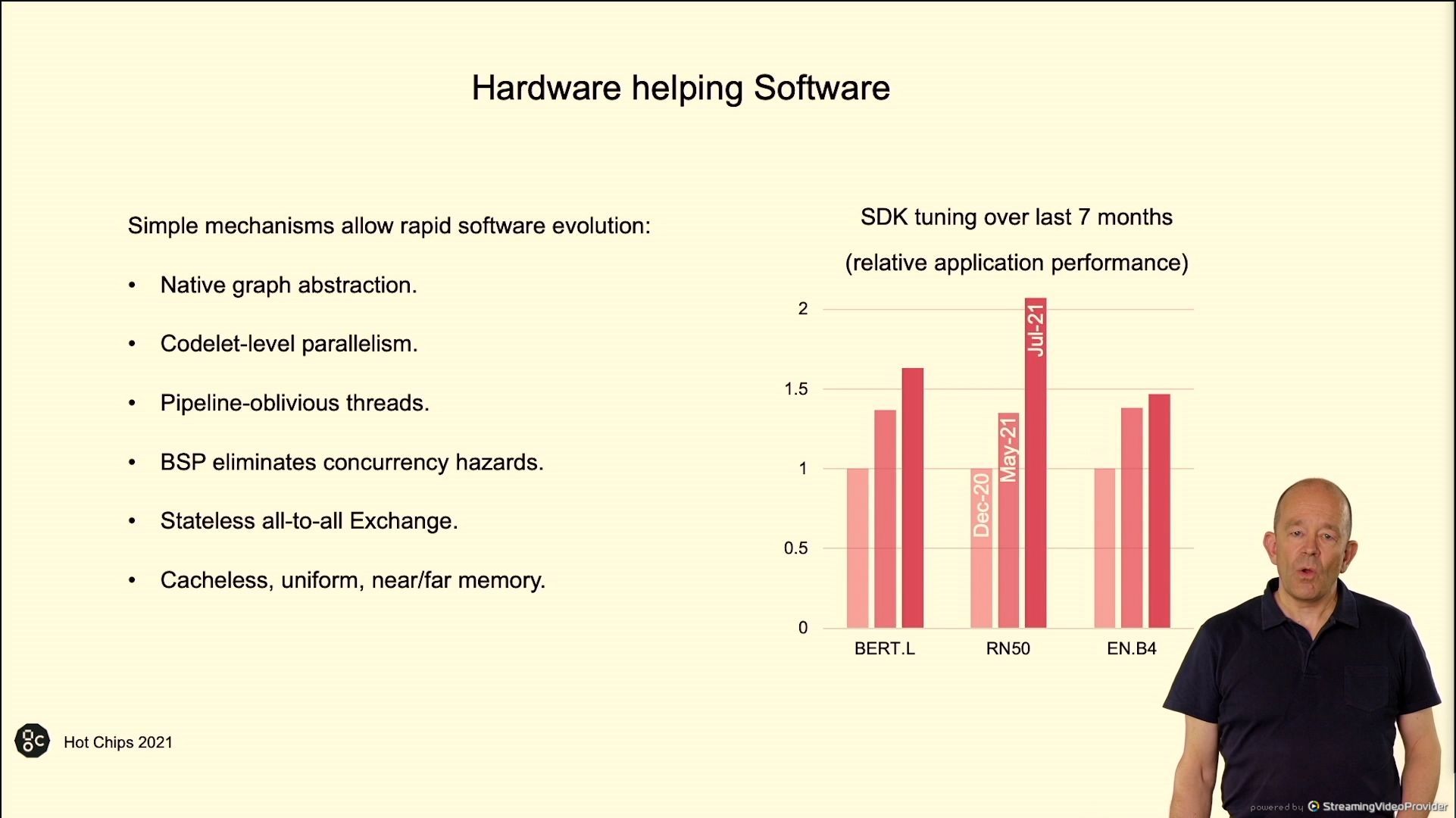
02:49PM EDT – Trace for program
02:49PM EDT – 60% cycles in compute, 30% in trade, 10% in sync. Depends on the algorithm
02:50PM EDT – Compiler load steadiness the processors
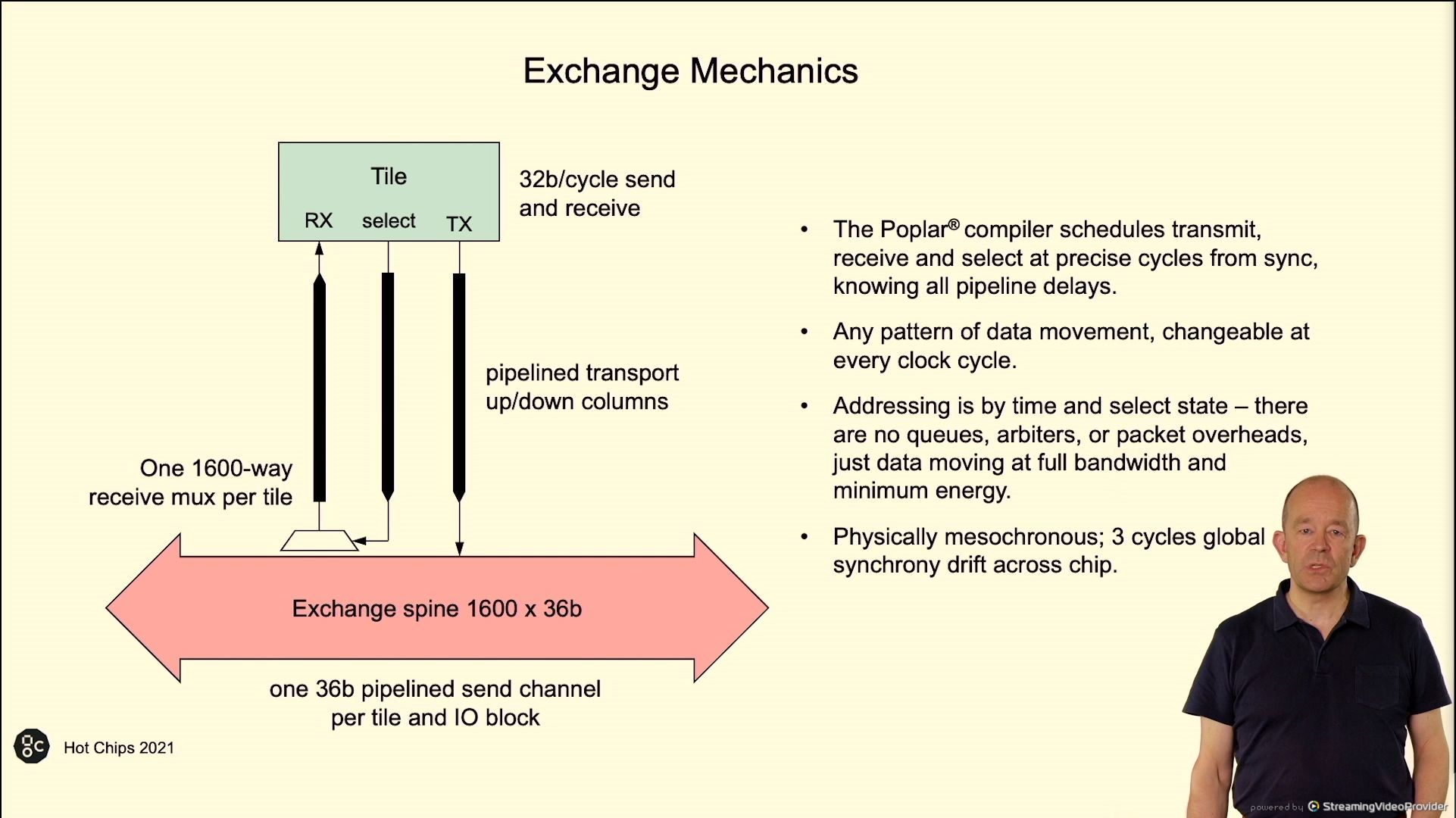
02:50PM EDT – Exchange backbone
02:50PM EDT – three cycle drift throughout chip
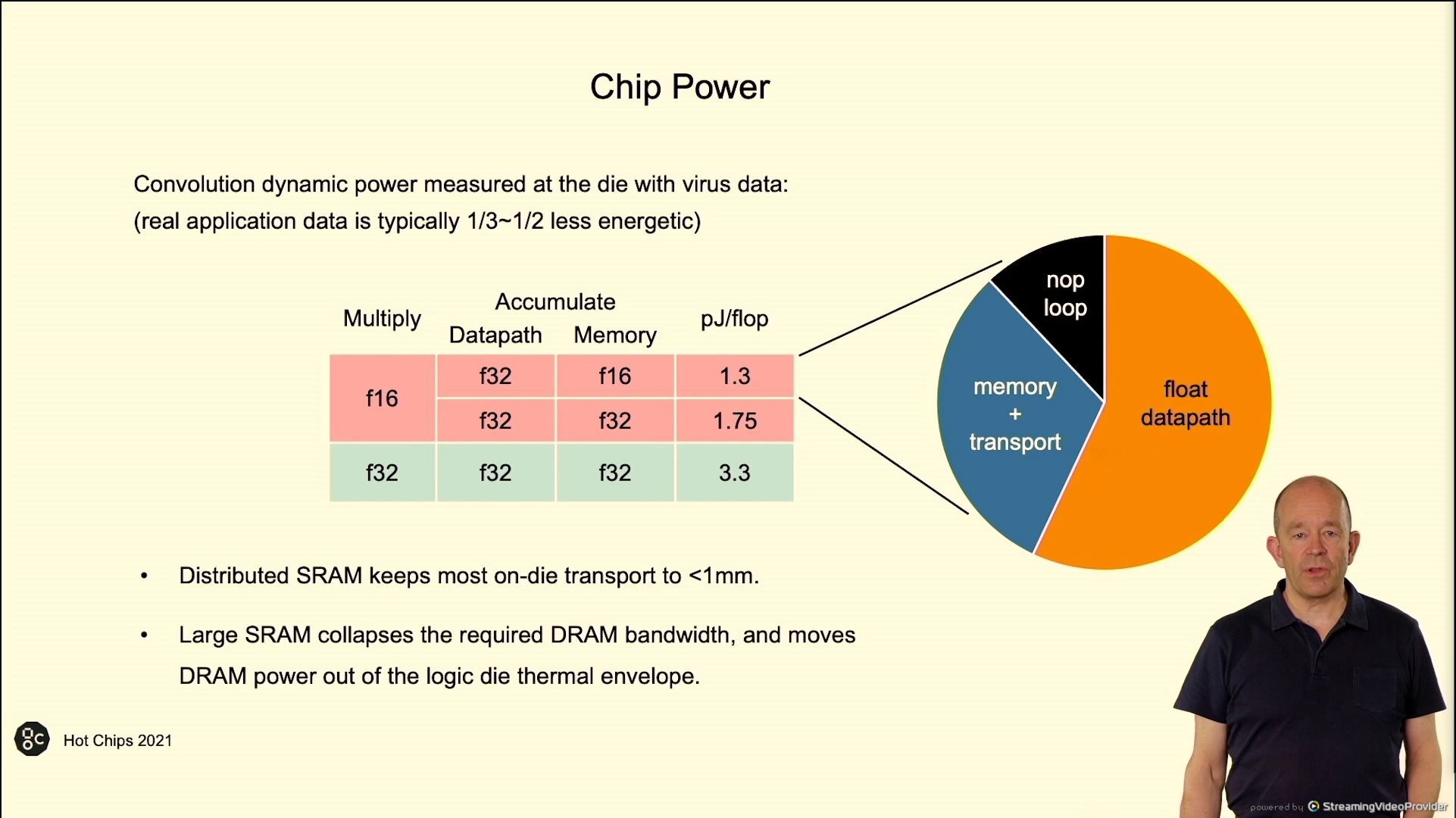
02:51PM EDT – Chip energy
02:51PM EDT – pJ/flop
02:52PM EDT – 60/30/10 within the pie chart
02:52PM EDT – arithmetic power dominates
02:52PM EDT – IPU extra environment friendly in TFLOP/Watt

02:53PM EDT – Not utilizing HBM – on die SRAM, low bandwidth DRAM
02:53PM EDT – DDR for mannequin capability
02:53PM EDT – HBM has a value drawback – IPU permits for DRAM
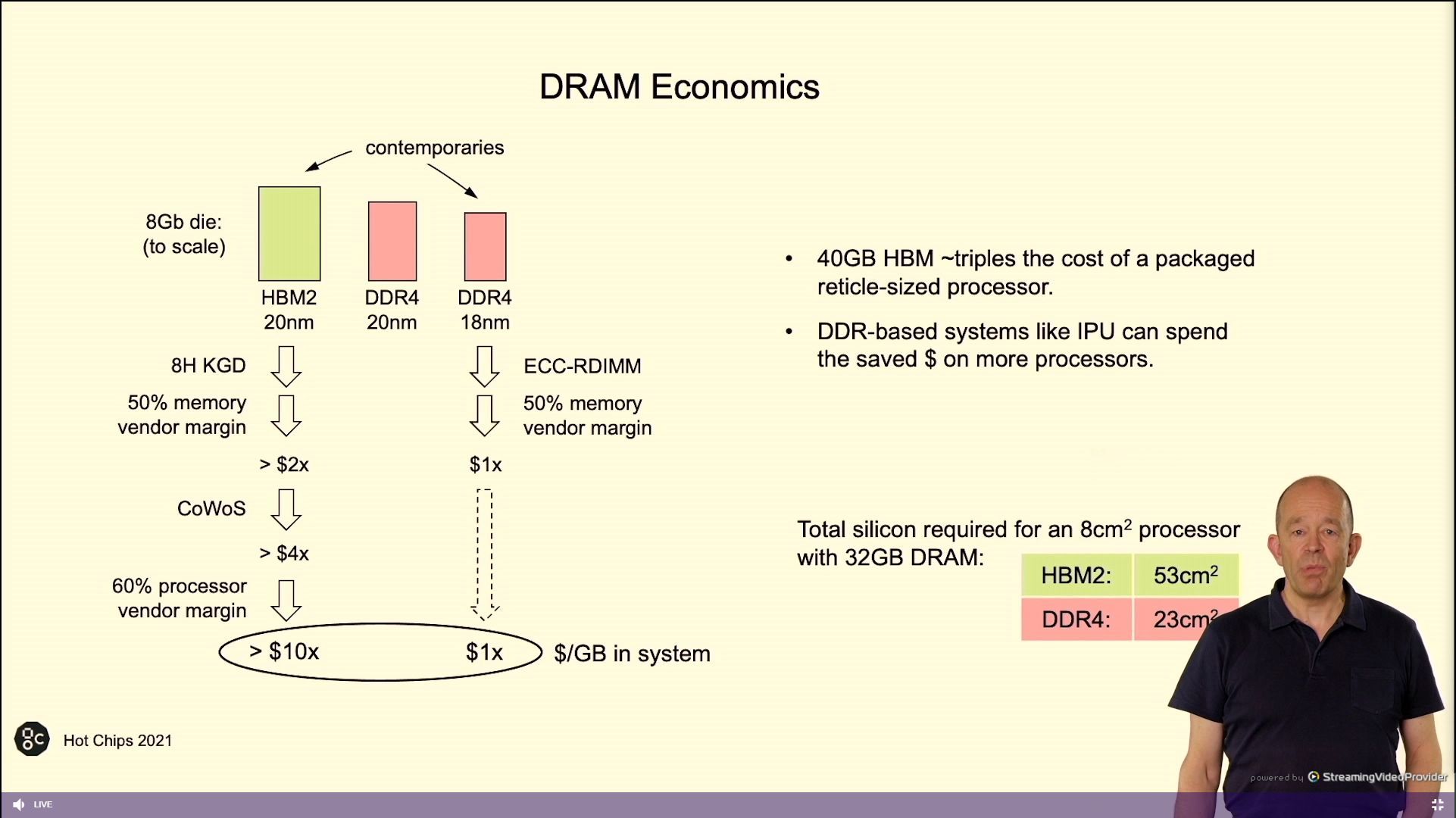
02:54PM EDT – 40 GB HBM triples the price of a processor
02:54PM EDT – Added value of CoWoS
02:54PM EDT – VEndor provides margin with CoWoS
02:54PM EDT – No such overhead with DDR
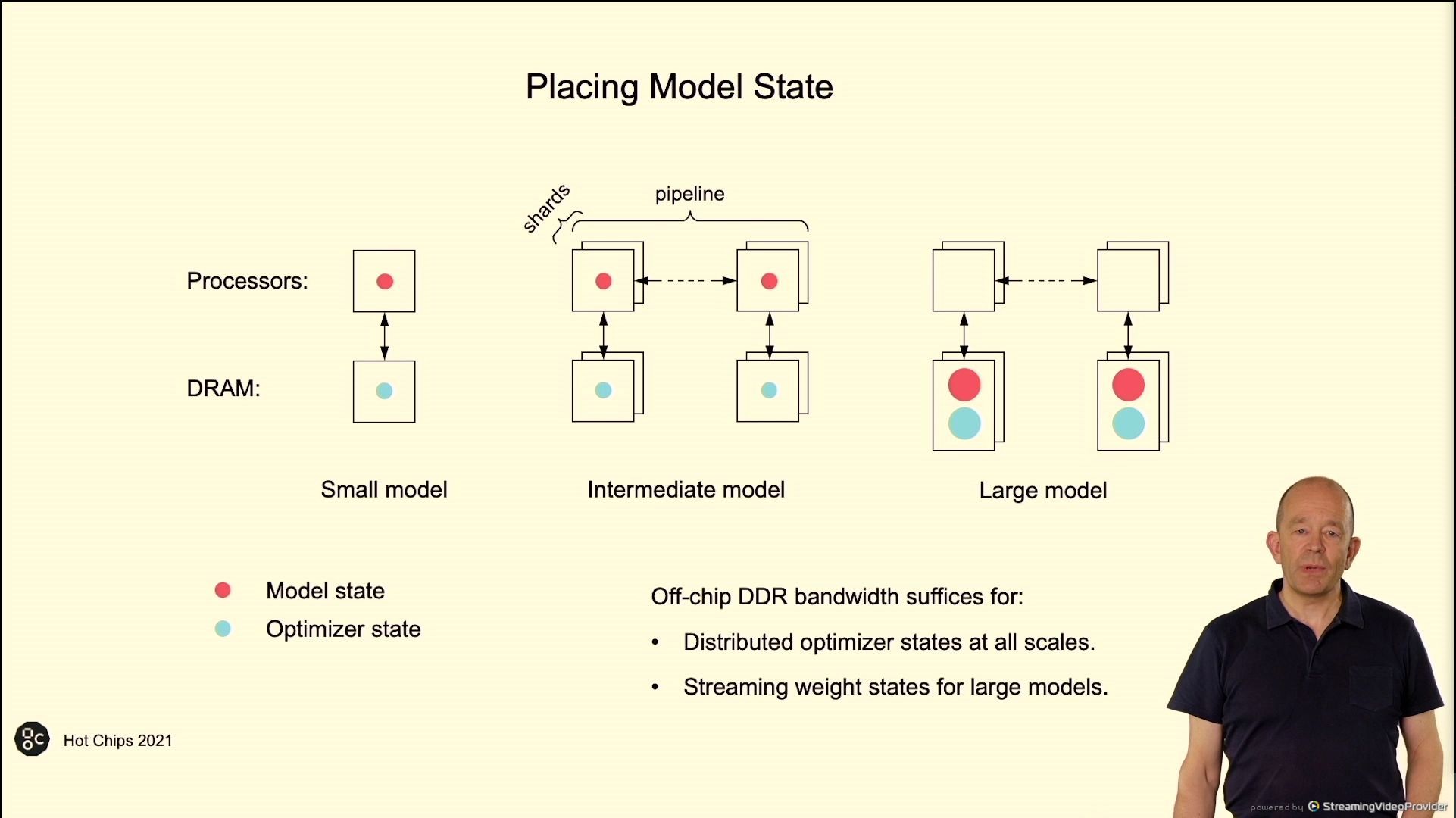
02:55PM EDT – Off-chip DDR bandwidth suffices for streaming weight states for giant fashions
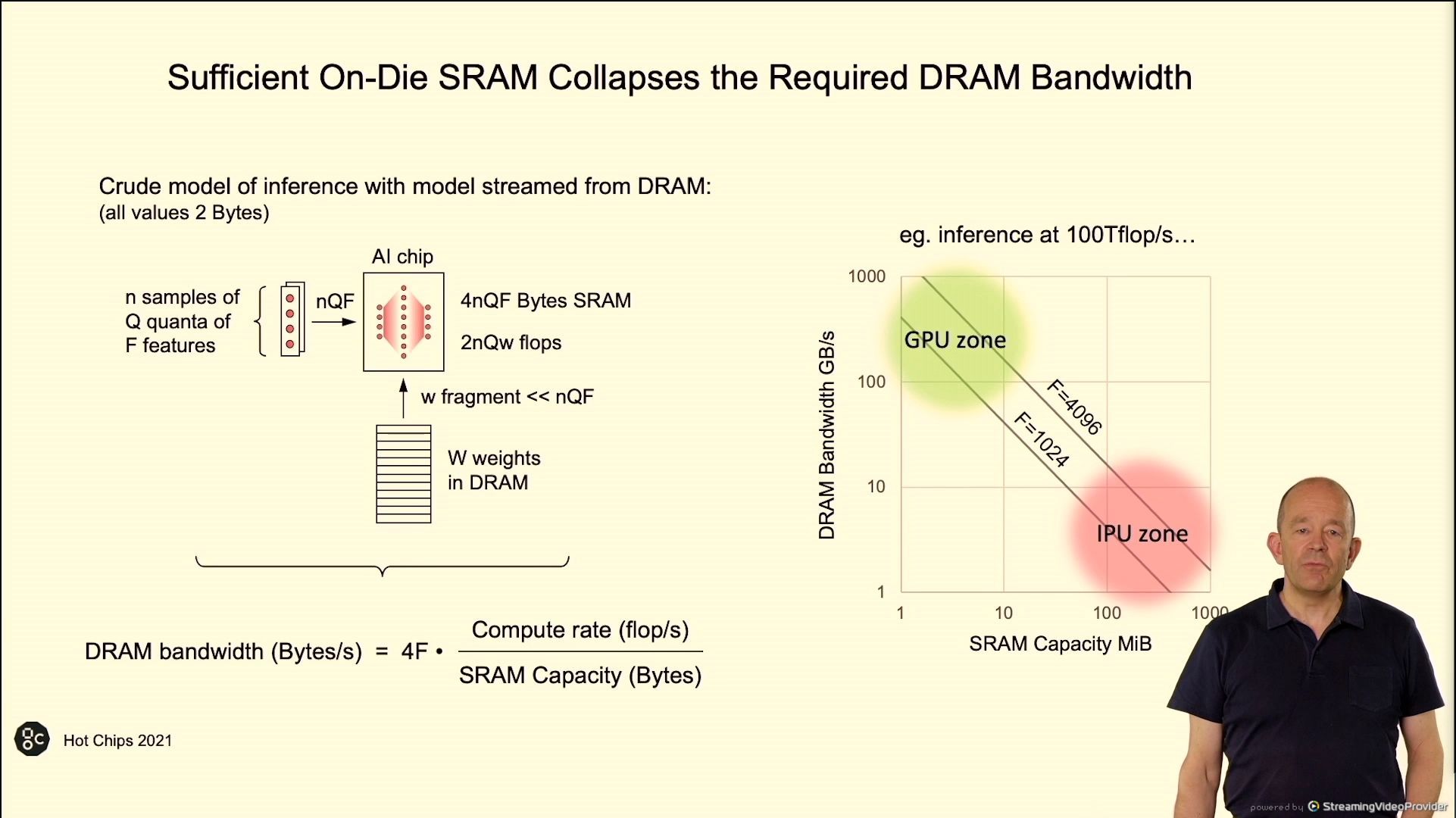
02:56PM EDT – More SRAM on chip means much less DRAM bandwidth wanted

02:58PM EDT – Q&A
03:00PM EDT – Q: Clocking is mesochrnous however static mesh – assume worst case clocking delays, or one thing else? A: Behaves as if syncronous. In follow, clocks and knowledge chase one another. Fishbone structure of trade it to make it easy
03:00PM EDT – Q: Are outcomes deterministic? A: Yes as a result of every thread and every tile has its personal seed. Can manually set seeds
03:05PM EDT – Next Talk is Cerebras
03:05PM EDT – WSE-2 new system configurations


03:06PM EDT – 2016 began, 2019 WSE-1

03:06PM EDT – 2.6 trillion transistors
03:06PM EDT – 850ok cores

03:07PM EDT – CS-2 system on sale at the moment
03:07PM EDT – it prices just a few million
03:07PM EDT – Traditional approaches…





