
05:28PM EDT – Welcome to Hot Chips! This is the annual convention all in regards to the newest, biggest, and upcoming large silicon that will get us all excited. Stay tuned throughout Monday and Tuesday for our common AnandTech Live Blogs.
05:31PM EDT – Stream is beginning! We have Intel, AMD, Google, Xilinx
05:32PM EDT – One of essentially the most advanced tasks at Intel

05:33PM EDT – Aiming for 500x over Intel’s earlier finest GPU
05:33PM EDT – Scale is essential

05:33PM EDT – Four variants of Xe
05:34PM EDT – Exascale market wants scale
05:34PM EDT – broad set of datatypes

05:34PM EDT – Xe-Core
05:34PM EDT – No longer EUs – Xe Cores now
05:35PM EDT – Each core in HPC has 8x 512-bit vectors, 8×4096-bit matrix engines, 8-deep systloic array
05:35PM EDT – Large 512 KB L1 cache per Xe Core
05:35PM EDT – Software configurable scratch pad shared reminiscence

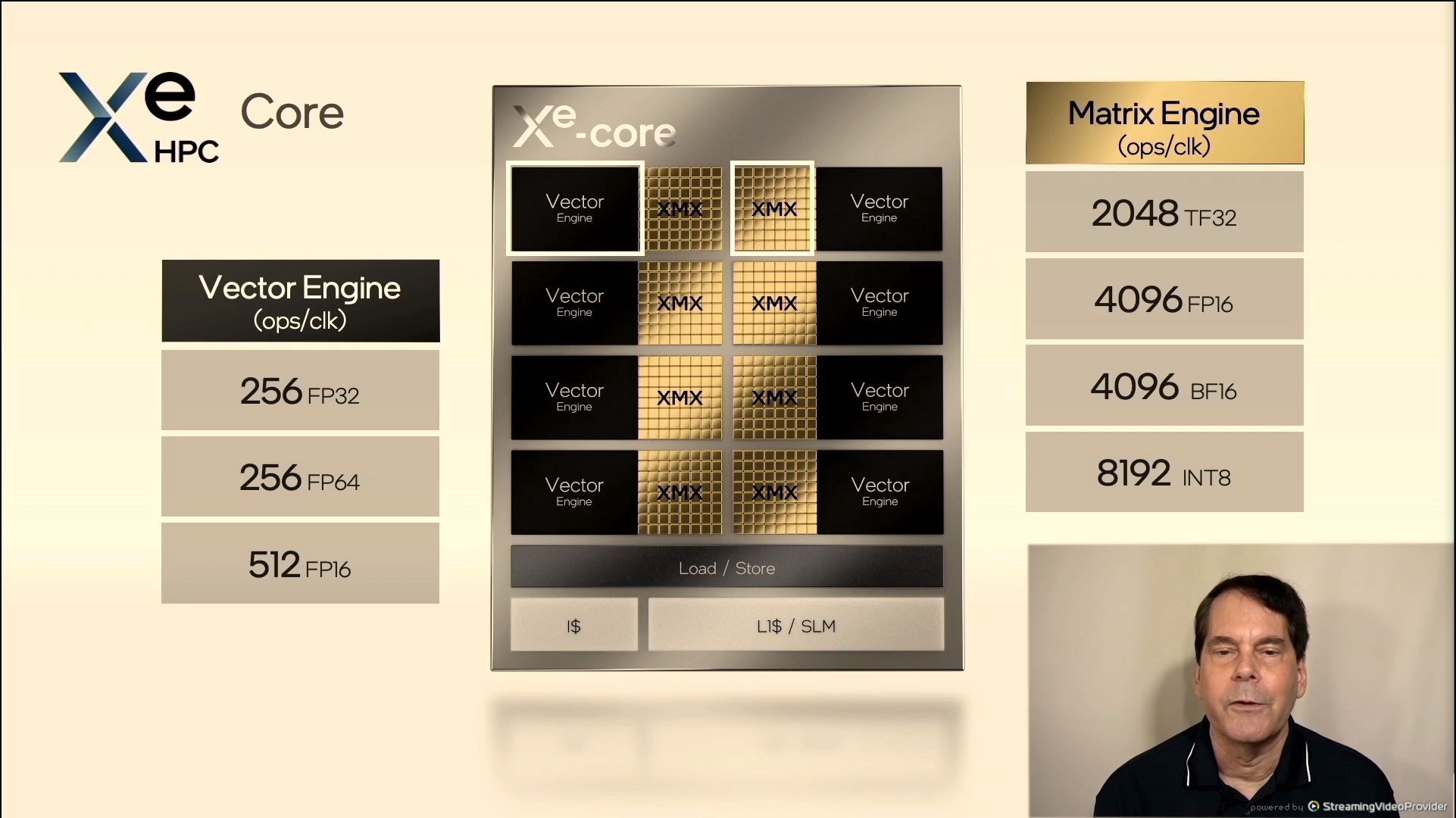
05:36PM EDT – 8192 x INT8 per Xe-Core
05:36PM EDT – One slice has 16 Xe Cores, 16 RT models, 1 {hardware} context

05:36PM EDT – ProVis and content material creation
05:37PM EDT – Stack is 4 Slices
05:37PM EDT – 64 Xe Cores, 64 RT Units, four {hardware} contextsd, L2 cache, four HBM2e controllers

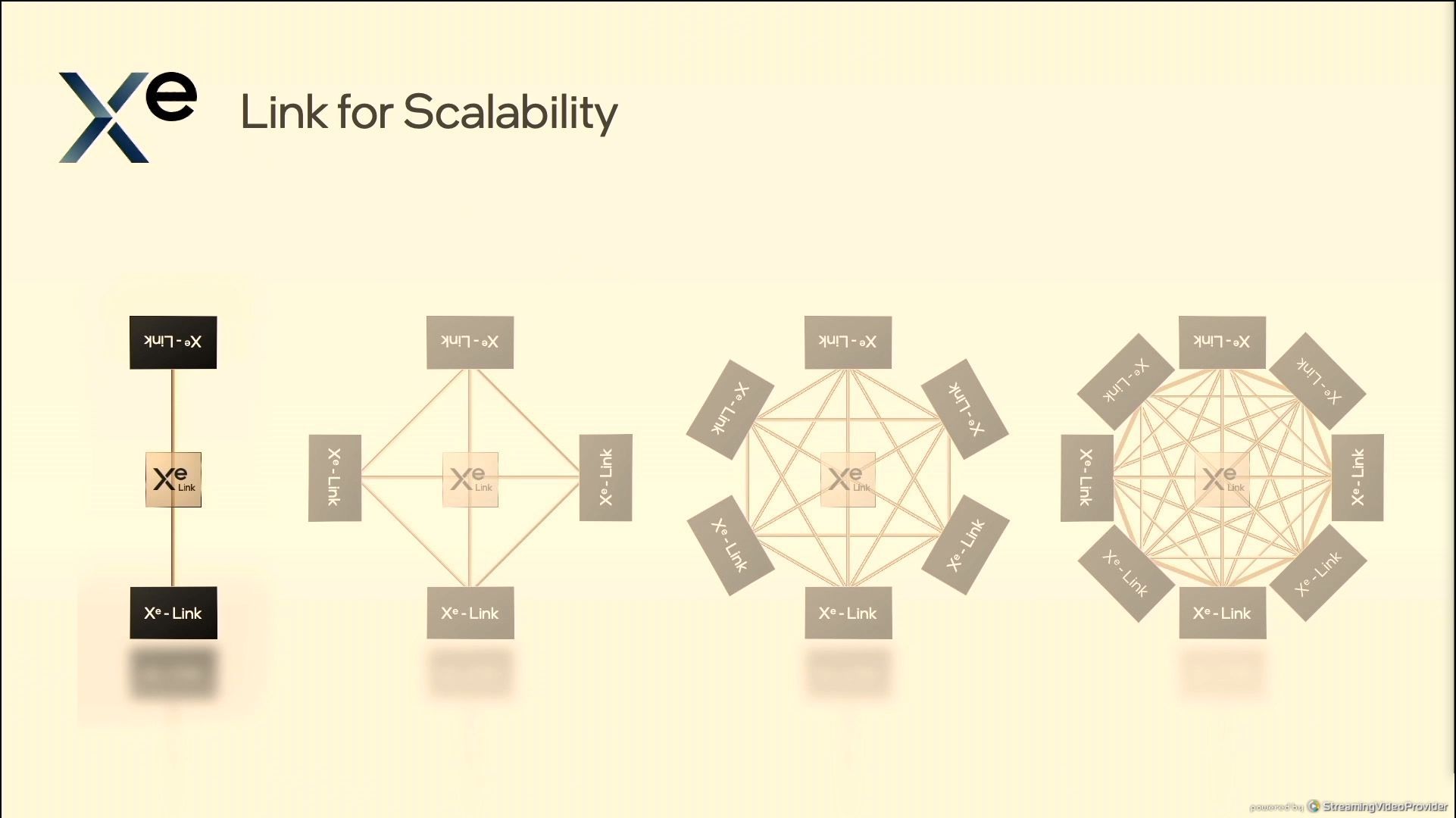
05:37PM EDT – 8 Xe Links
05:37PM EDT – Support 2 stacks

05:38PM EDT – related straight by means of packaging

05:38PM EDT – GPU to GPU communication
05:38PM EDT – Eight absolutely related GPUs by means of embedded swap
05:38PM EDT – not for CPU-to-GPU
05:39PM EDT – Eight GPUs in OAM
05:39PM EDT – OCP Accelerator Module
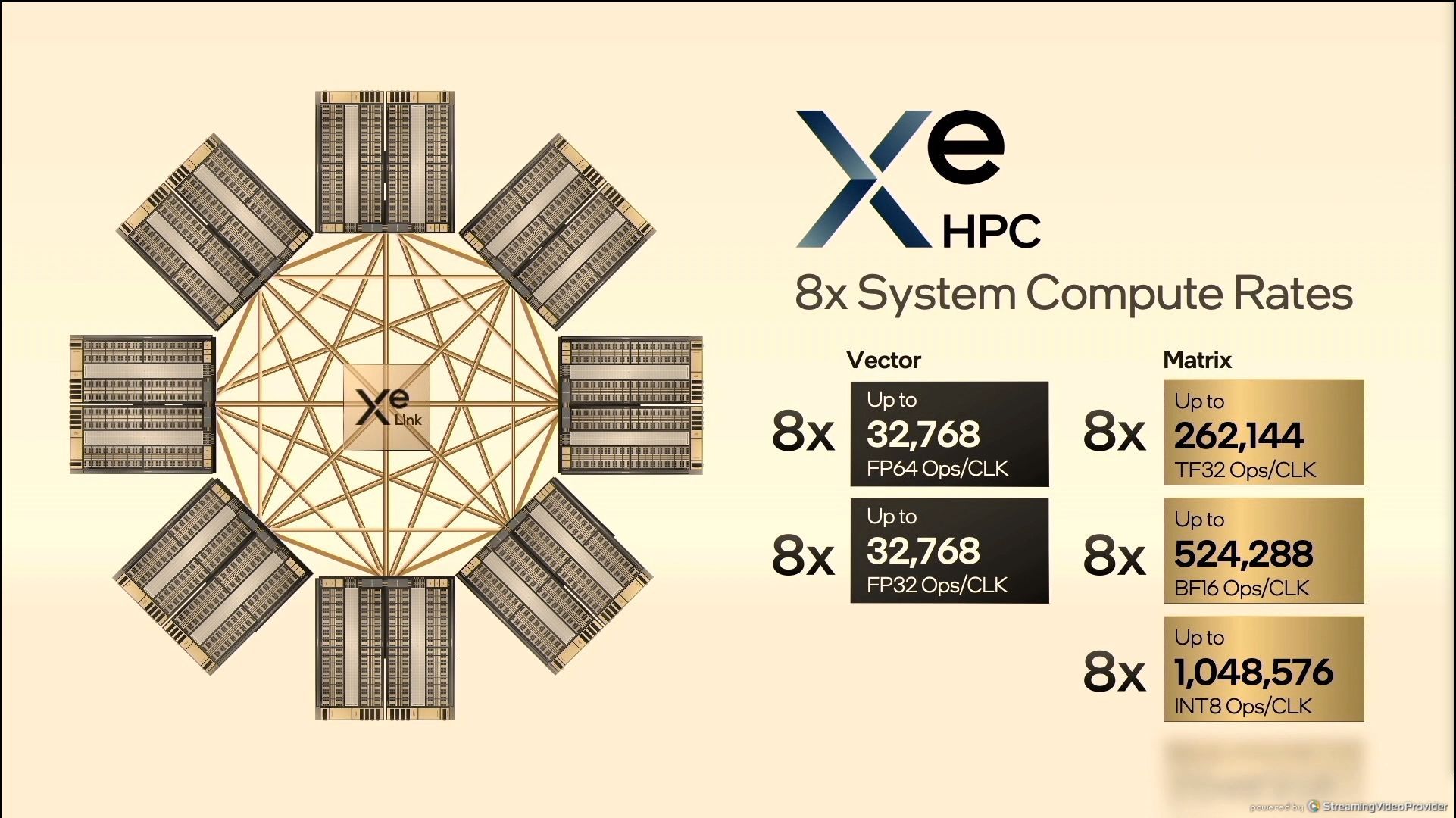
05:39PM EDT – 1 million INT8/clock in a single system

05:40PM EDT – Advanced packaging

05:41PM EDT – Lots of recent stuff
05:41PM EDT – EMIB + Foveros

05:41PM EDT – 5 totally different course of nodes
05:42PM EDT – MDFI interconnect site visitors
05:42PM EDT – a number of challenges

05:42PM EDT – Learned so much
05:43PM EDT – Floorplan locked very early
05:43PM EDT – Run Foveros at 1.5x frequency initially thought to attenuate foveros connections
05:43PM EDT – booted a couple of days after first silicon again
05:44PM EDT – Order of magnitude extra Foveros connections than different earlier designs


05:44PM EDT – Compute tiles constructed on TSMC N5

05:45PM EDT – 640mm2 per base tile, constructed on Intel 7

05:46PM EDT – Xe Link Tile inbuilt lower than a yr

05:47PM EDT – OneAPI help

05:47PM EDT – 45 TFLOPs of sustained perf


05:48PM EDT – Customers early subsequent yr
05:48PM EDT – Q&A
05:50PM EDT – Q: PV of 45TF FP32 compute – 45 TF of FP64? A: Yes
05:51PM EDT – Q: More insights into {hardware} context – is 8x PV monolithic or 800 cases? A: Looks like a single logical system, impartial functions can run in isolation in context stage
05:53PM EDT – Q: Does Xe Link help CXL, in that case, which revision? A: nothing to do with CXL
05:54PM EDT – Q: Does the GPU connect with CPU by PCIe or CXL? A: PCIe
05:54PM EDT – Q: Xe Link bandwidth? A: 90G serdes
05:55PM EDT – Q: Peak energy/TDP? A: Not disclosing – no product particular numbers
05:55PM EDT – Next speak up is AMD – RDNA2


05:57PM EDT – CDNA for compute vs RDNA for gaming
05:57PM EDT – Both are centered on compute for every route
05:58PM EDT – Flexible and adaptable design

05:58PM EDT – 18 months after first RDNA product
05:59PM EDT – 128 MB of Infinity cache
05:59PM EDT – improve frequency
05:59PM EDT – RDNA unshackled the design from sure underpinnings of GCN
05:59PM EDT – Perf/W is vital metric
05:59PM EDT – reduce wasted energy
06:00PM EDT – DX12 Ultimate help, help for DirectStorage
06:00PM EDT – Next gen consoles helped with improvement of featureset
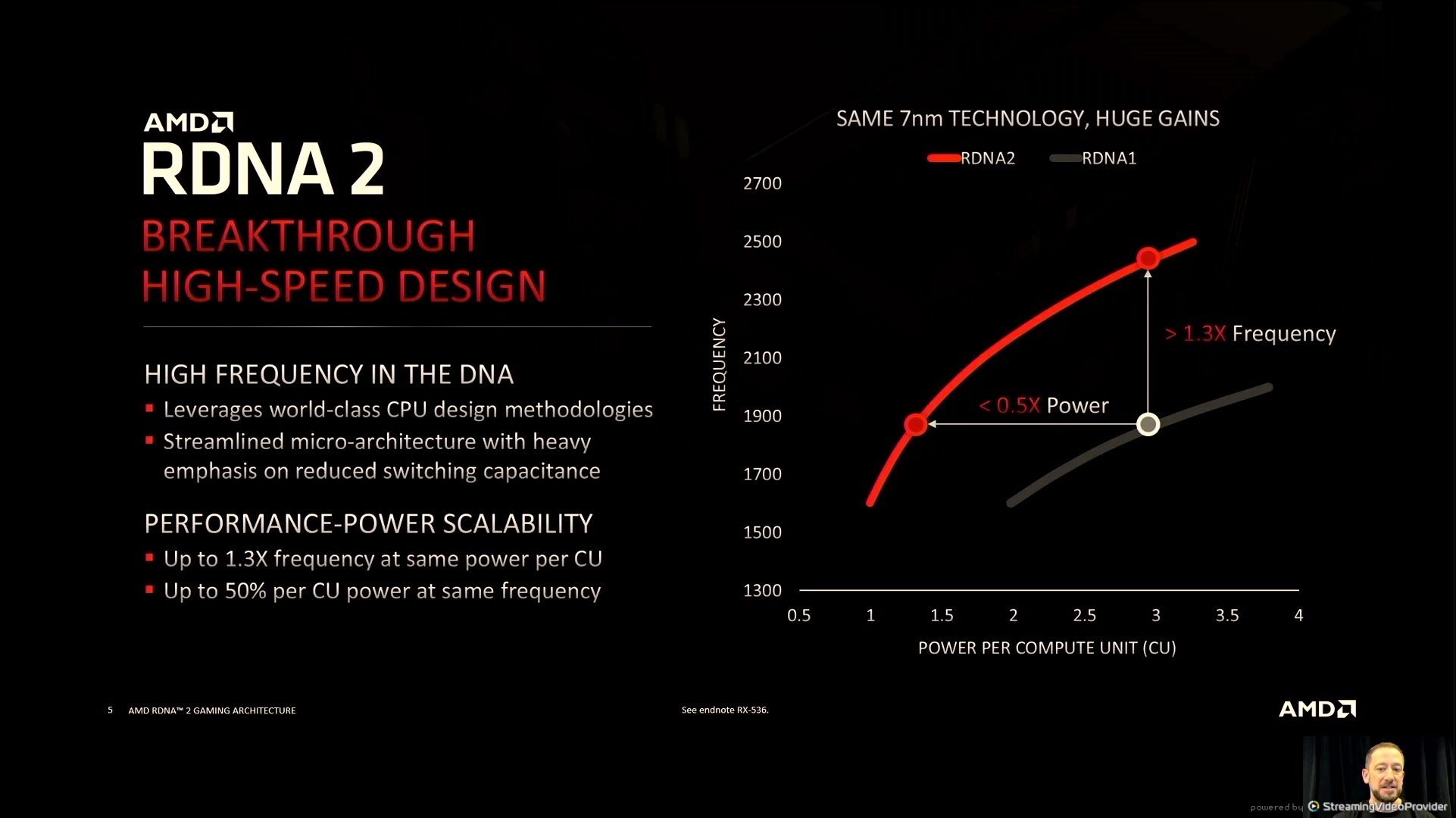
06:01PM EDT – +30% Freq at iso-power, or beneath half energy for isofrequency
06:02PM EDT – All performed with out change in course of node

06:03PM EDT – RX5000 – RDNA1 – excessive bandwidth however low hit charges
06:04PM EDT – Trying to keep away from GDDR use to cut back energy – so enhance caches!

06:04PM EDT – GPU cache hit charges
06:04PM EDT – graphics was once one-pass compute

06:05PM EDT – Big L3 caches
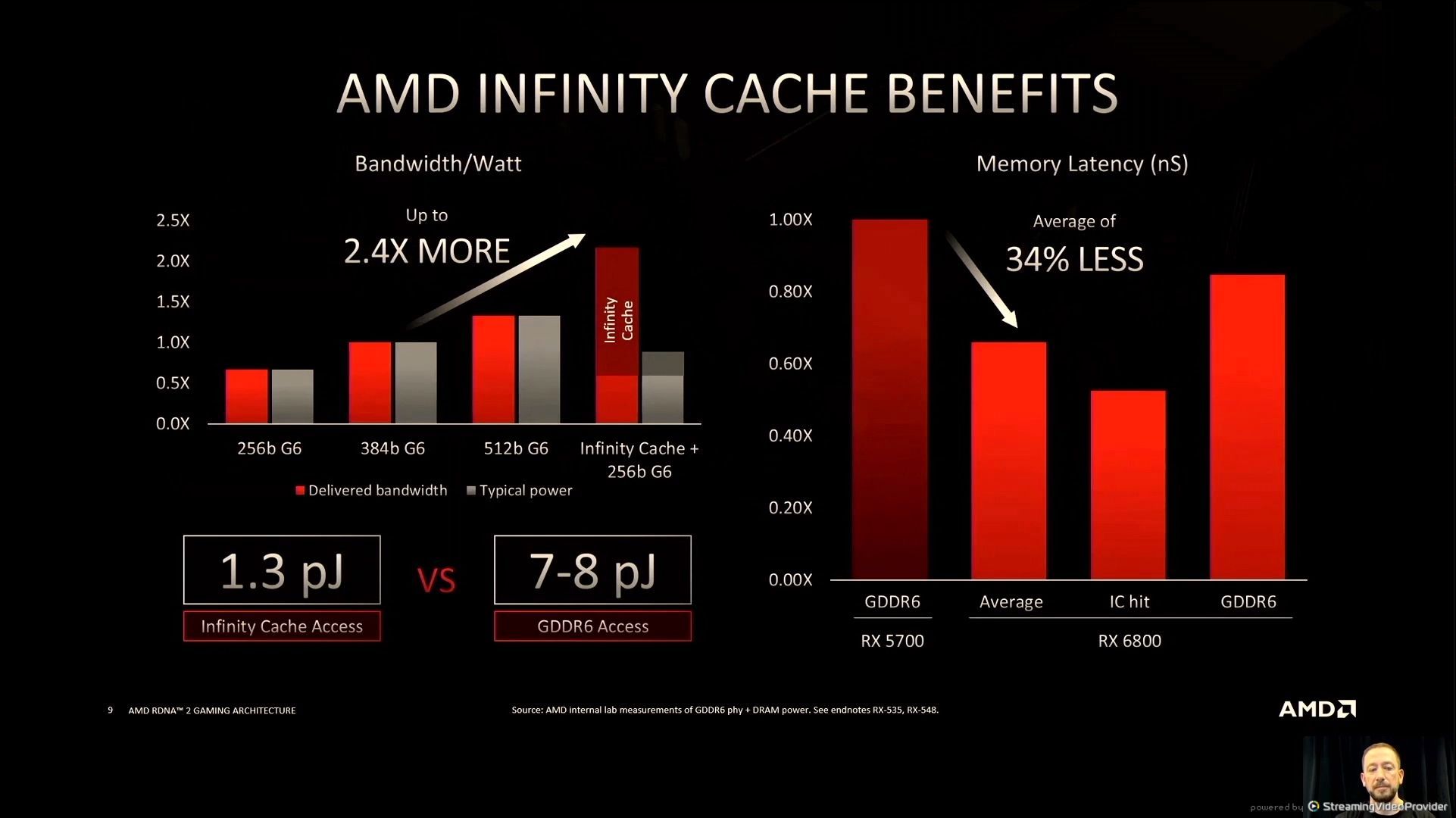
06:07PM EDT – decrease power per bit – only one.3…





