
05:27PM EDT – Welcome to Hot Chips! This is the annual convention all in regards to the newest, biggest, and upcoming huge silicon that will get us all excited. Stay tuned throughout Monday and Tuesday for our common AnandTech Live Blogs.
05:30PM EDT – Just ready for this session to begin, ought to be a few minutes
05:30PM EDT – Arm up first with its Neoverse N2 cores

05:34PM EDT – Roadmap, goals, core structure, system structure, efficiency, conclusions
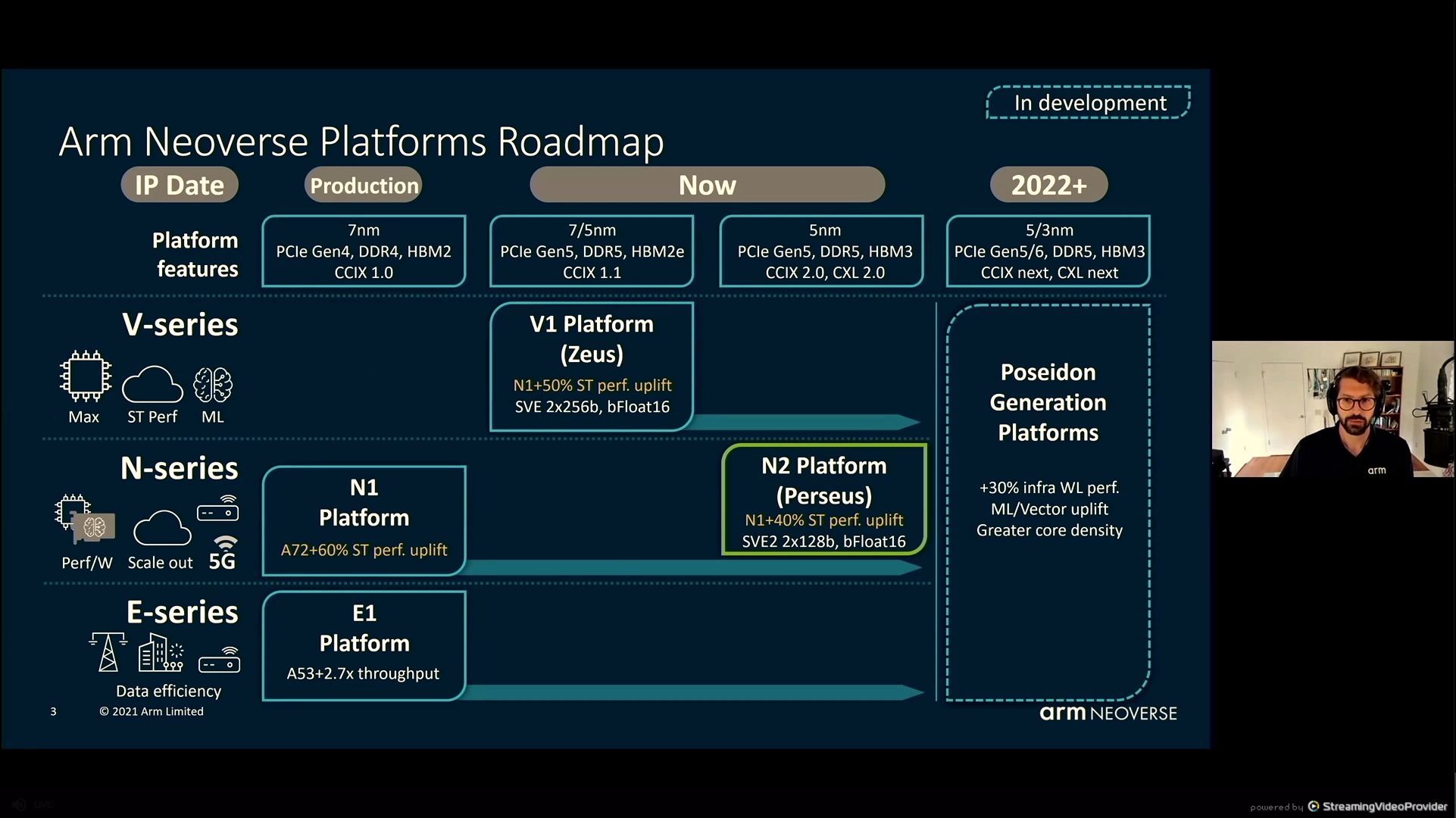
05:34PM EDT – Second technology infrastructure followiung N1
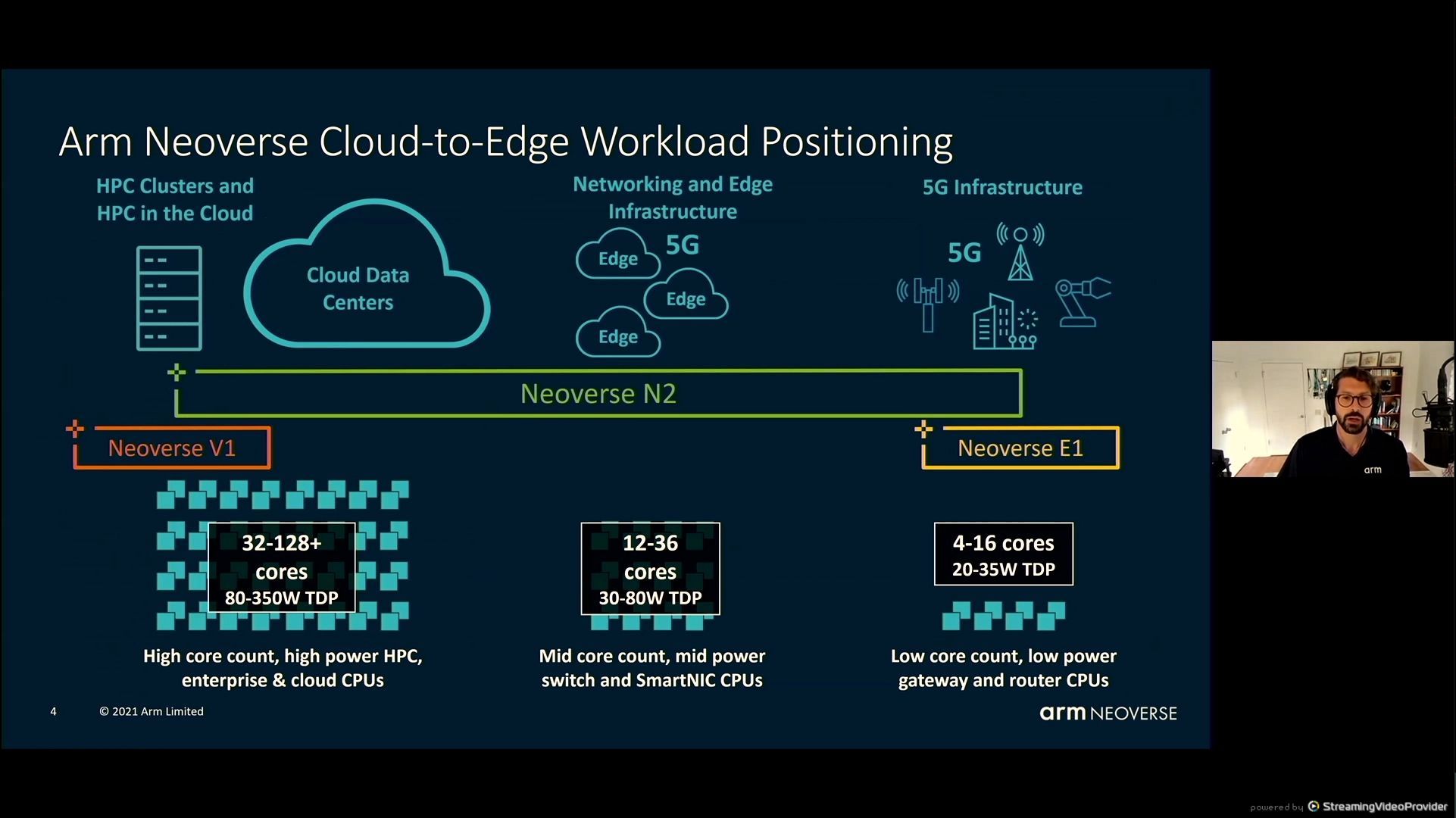
05:34PM EDT – 4-128 core designs
05:35PM EDT – 5G infrastructure to cloud information facilities
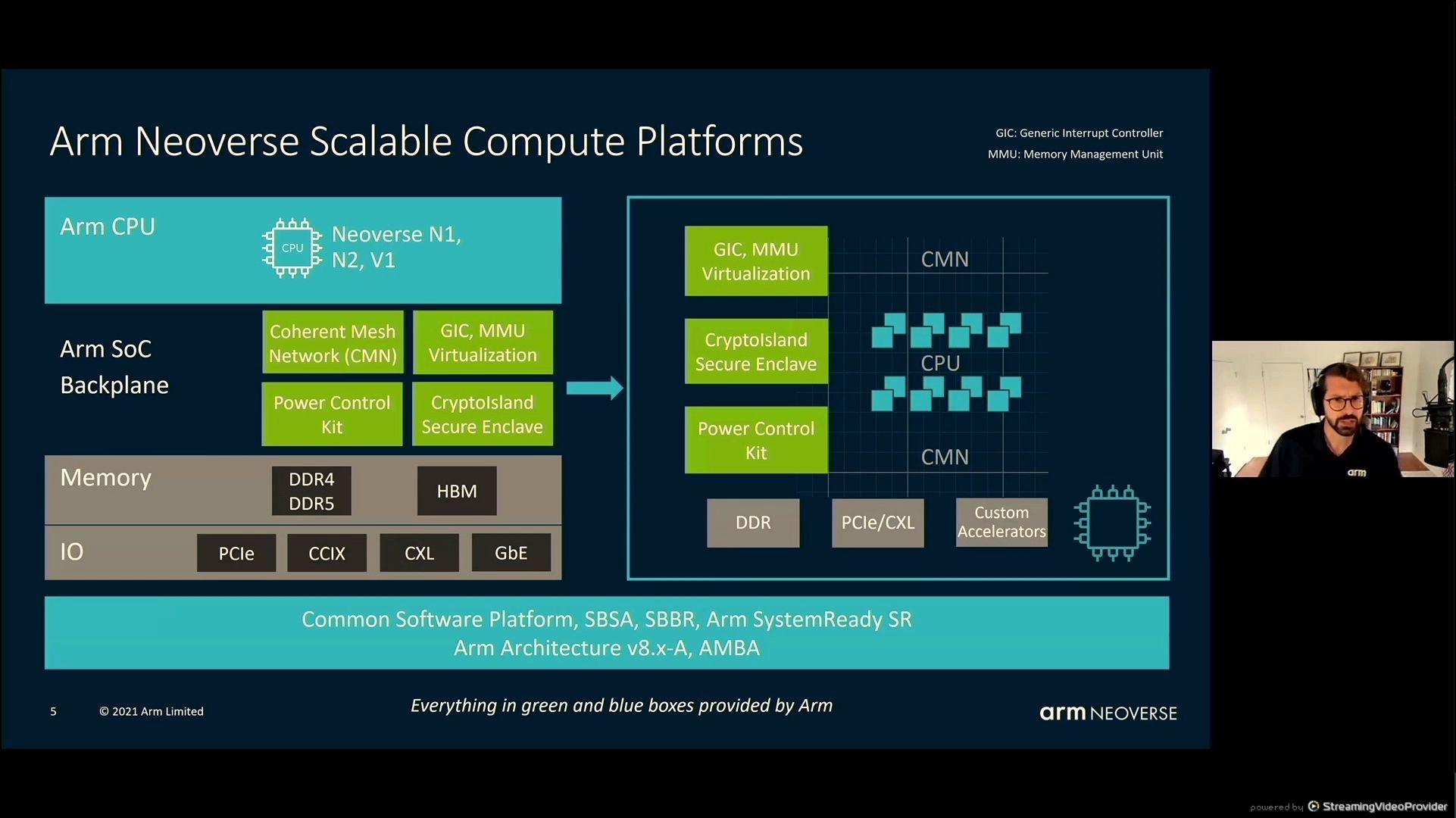
05:35PM EDT – Arm sells IP and definitions
05:35PM EDT – SBSA/SBBR help

05:36PM EDT – Marvell is already utilizing N2, as much as 36 in an SoC
05:36PM EDT – High pace packet processing

05:36PM EDT – All about SpecINT rating with DDR5 and PCIe 5.0

05:37PM EDT – N2 with Arm v9
05:37PM EDT – Two a lot of Scalable Vector Extensions, SVE, SVE2
05:37PM EDT – BF16 help, INT8 mul
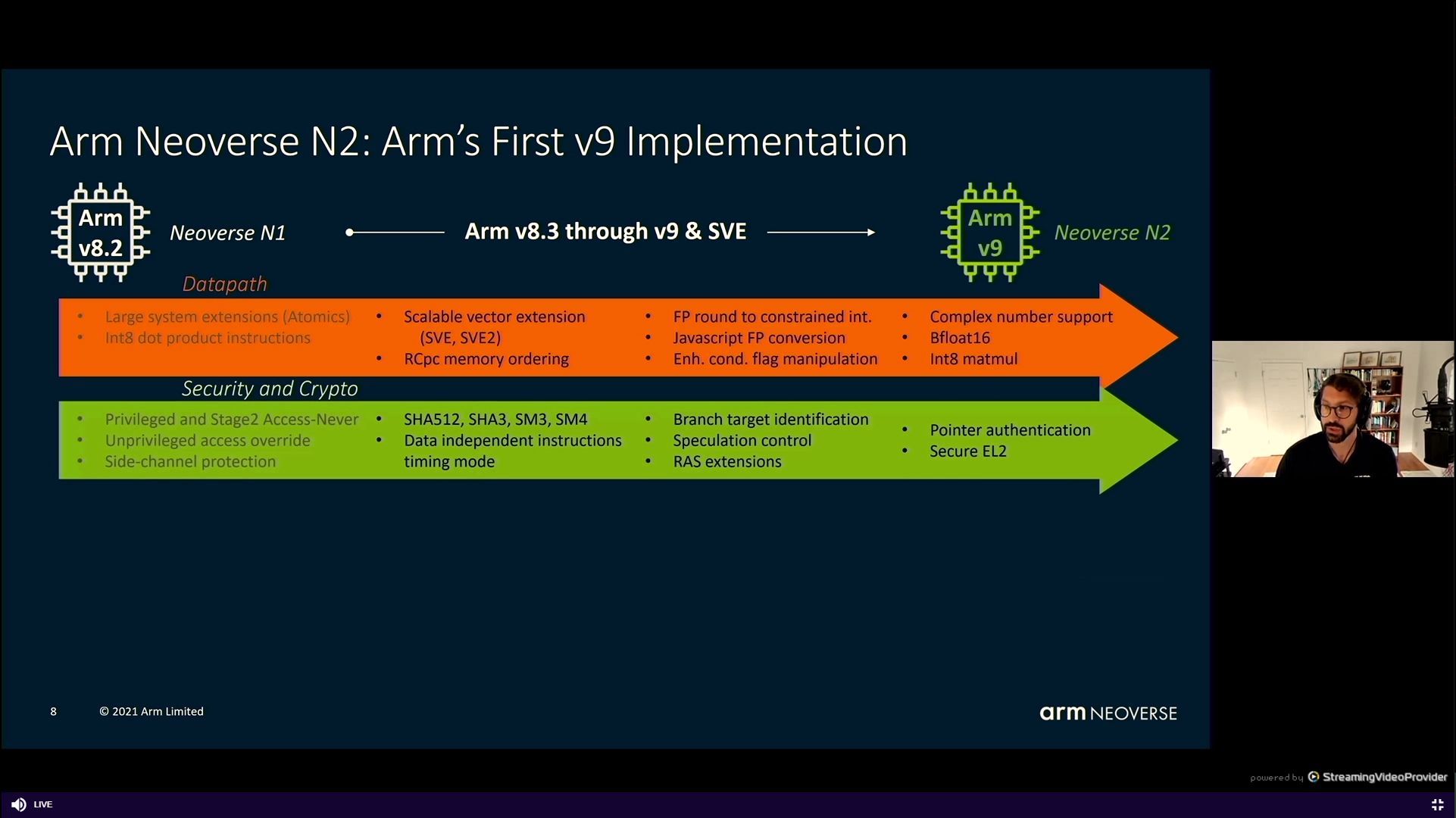
05:38PM EDT – Side channel safety, SHA, SM3/4
05:38PM EDT – *SHA3/SHA512
05:38PM EDT – Persistent reminiscence help
05:38PM EDT – reminiscence partition and monitoring
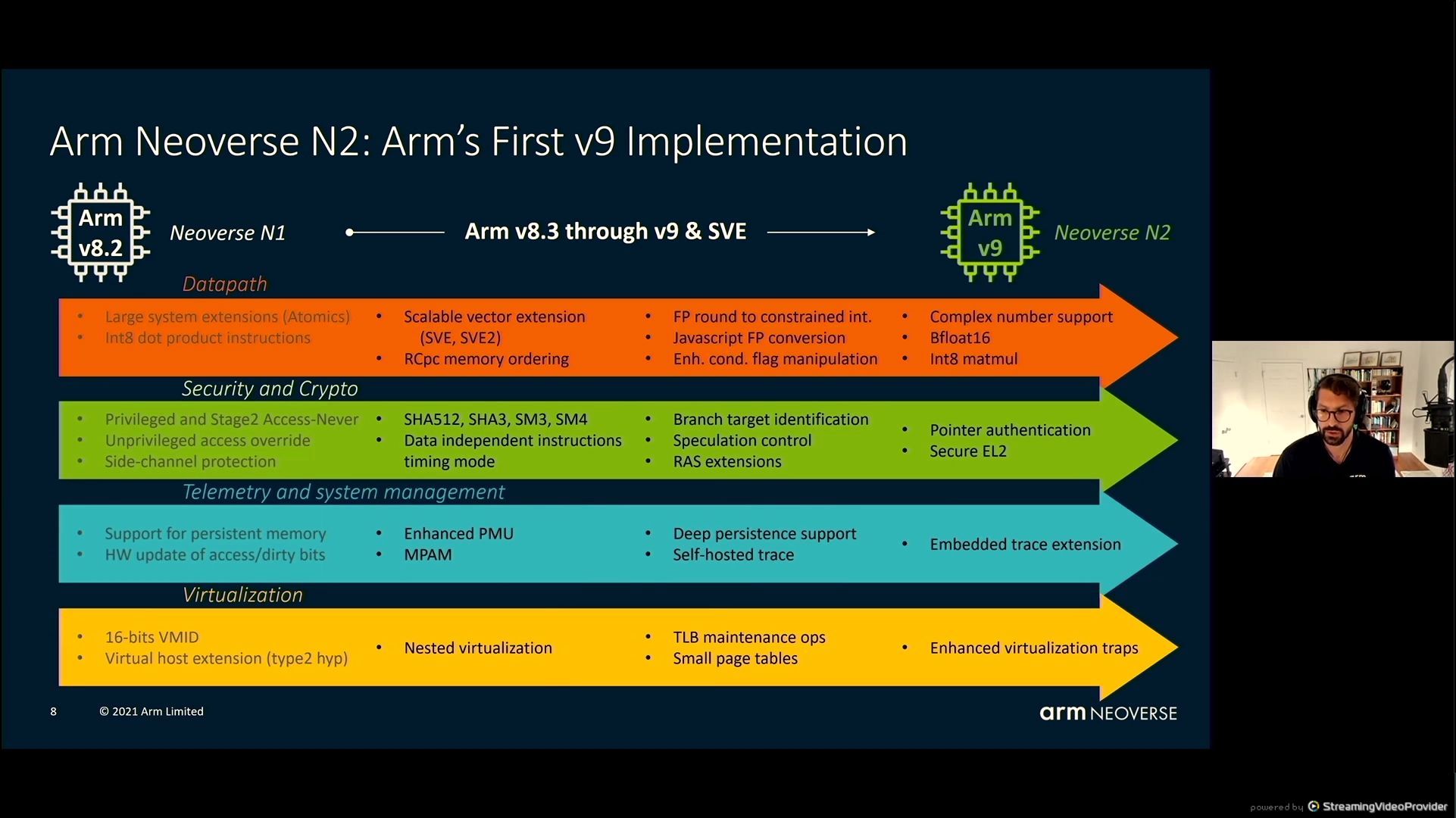
05:39PM EDT – Gen on gen enhancements with virtualization
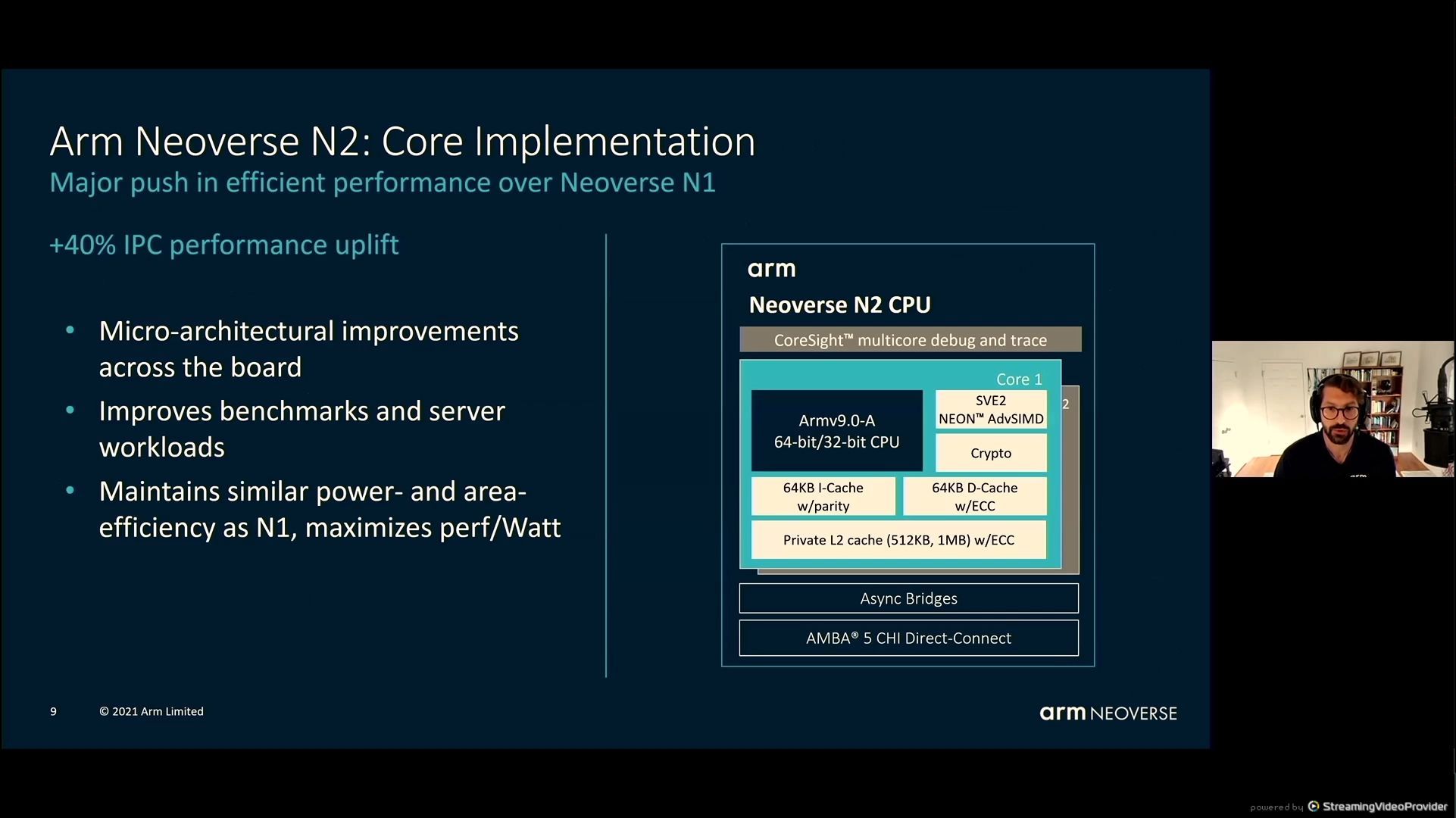
05:39PM EDT – +40% IPC uplift
05:39PM EDT – Similar energy/space as N1, maximizes perf/Watt
05:39PM EDT – an intense PPA trajectory
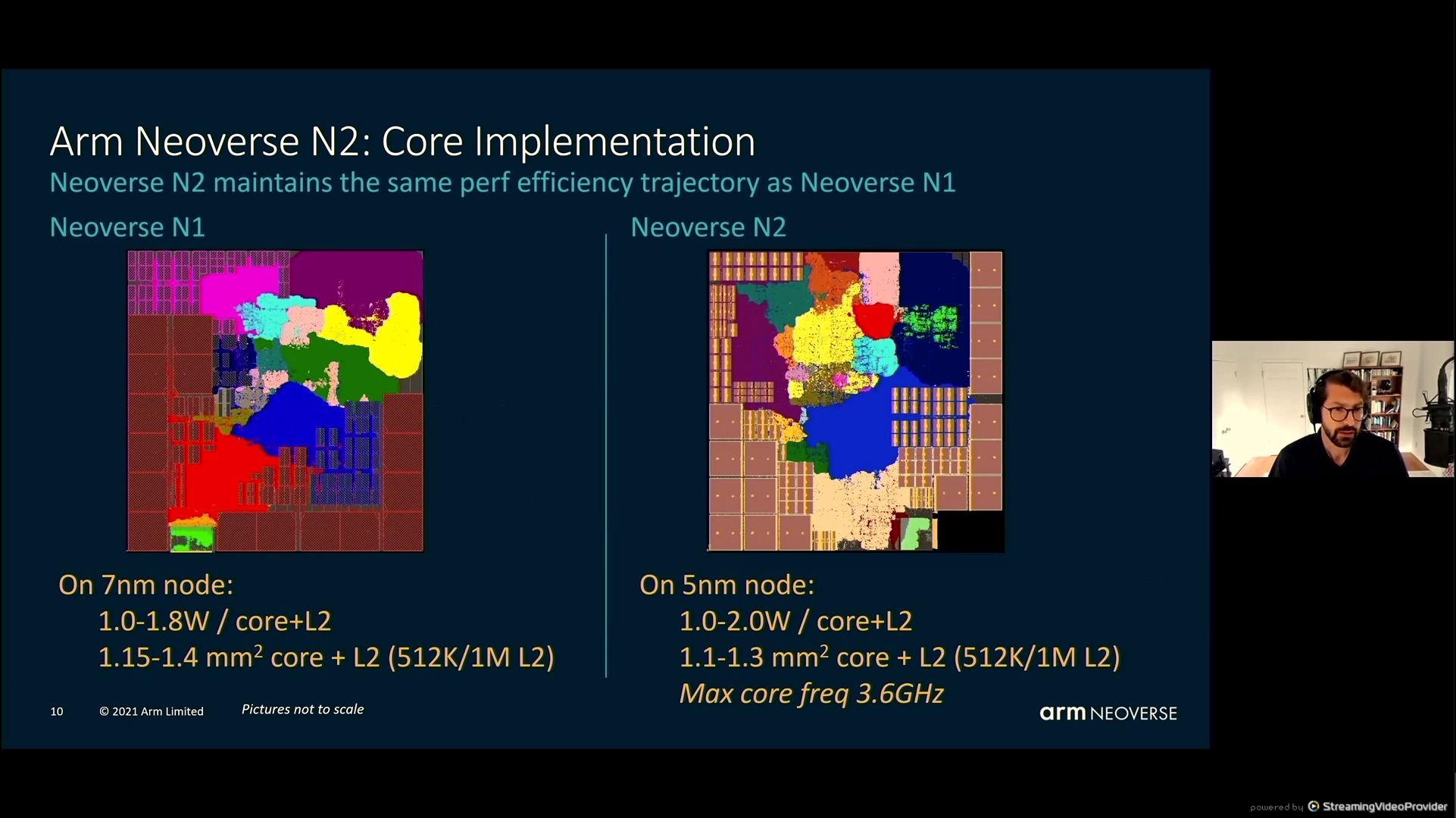
05:40PM EDT – 3.6 GHz max core frequency
05:40PM EDT – N1 on 7nm, vs N2 on 5nm
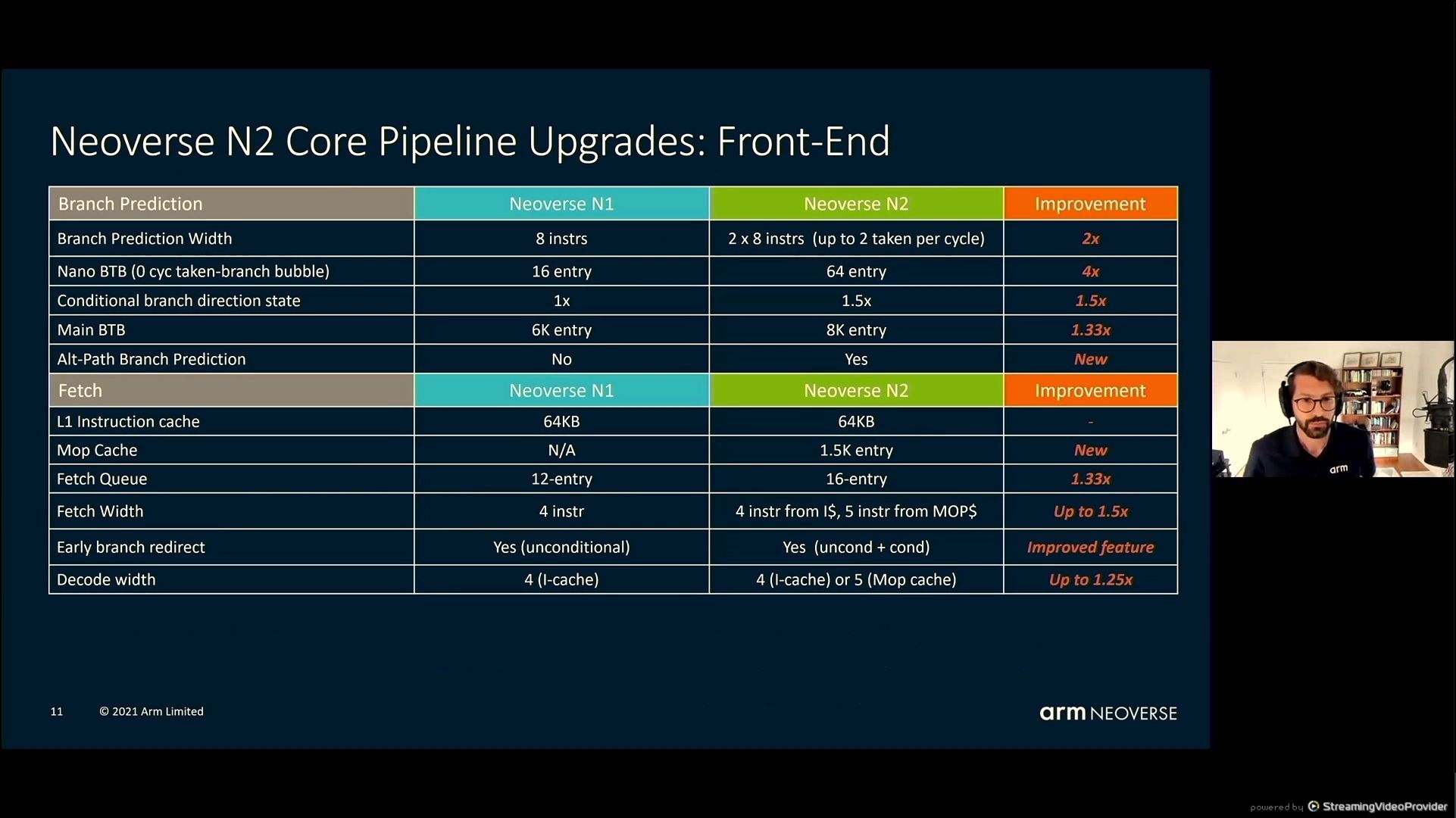
05:41PM EDT – uArch – Most buildings are biggers
05:41PM EDT – greater
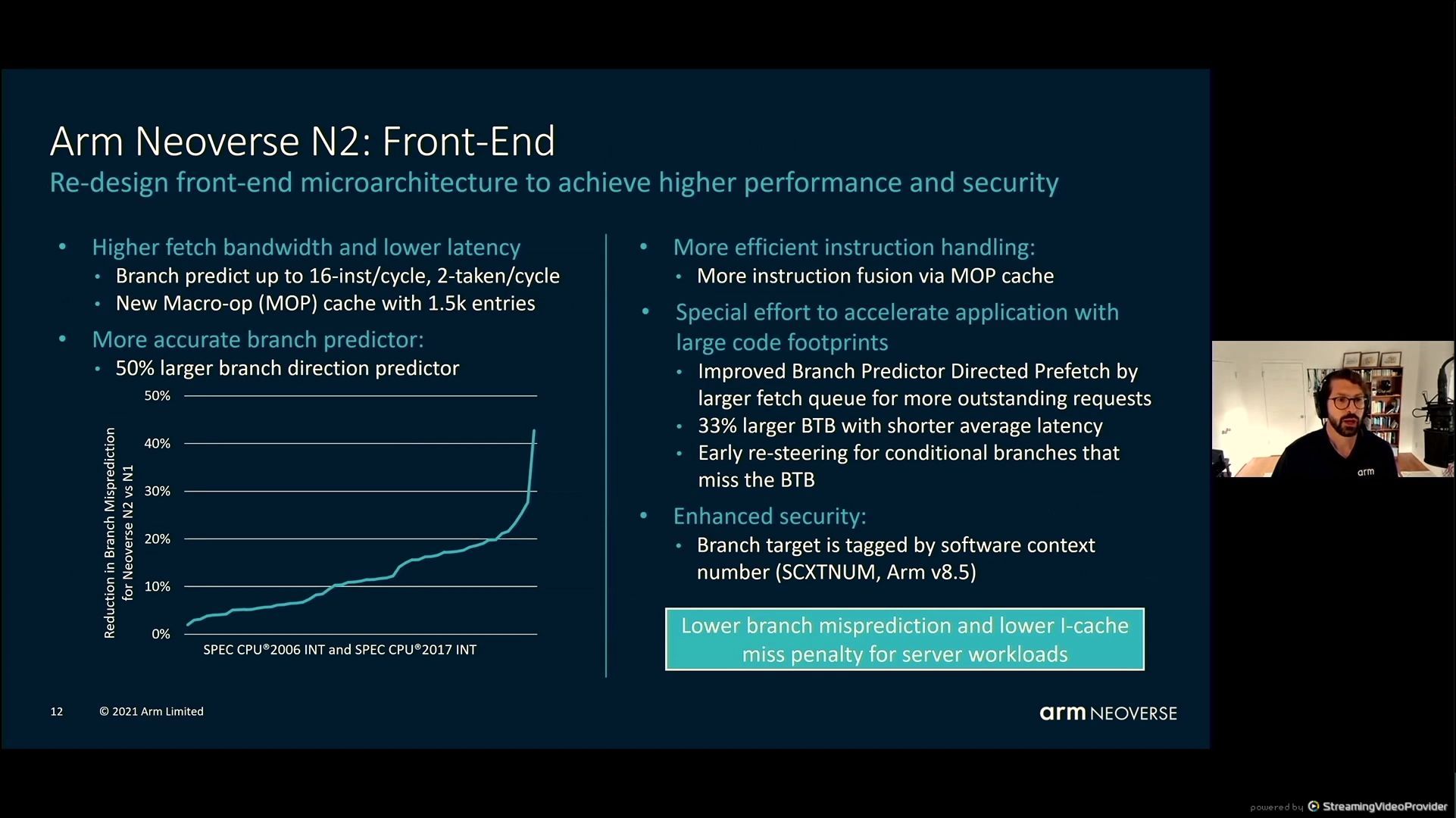
05:42PM EDT – Fetch extra per cycle on the entrance finish – enhance department prediction accuracy
05:42PM EDT – Enhanced safety to forestall side-channel
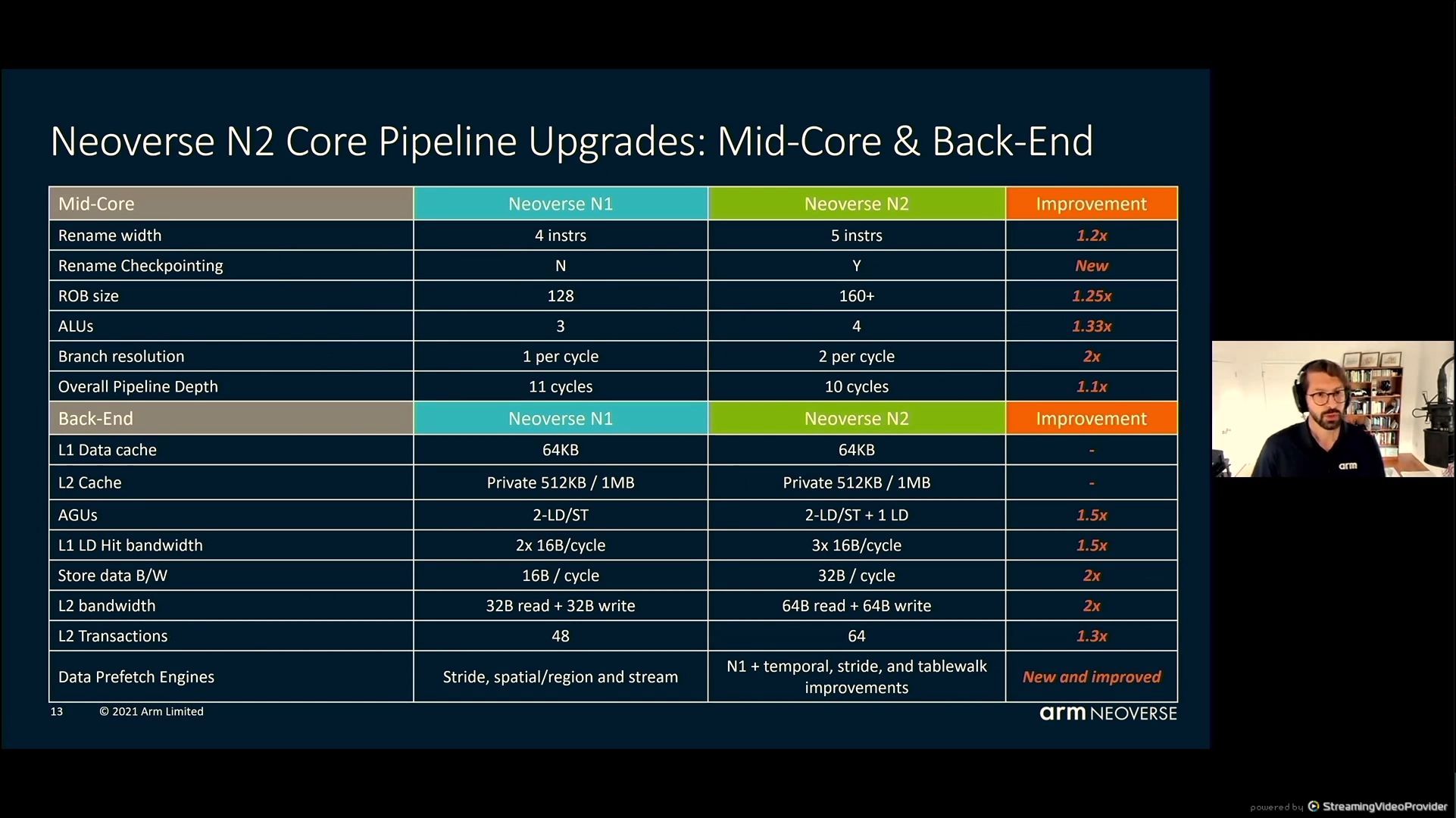
05:43PM EDT – More greater buildings on the again finish
05:44PM EDT – N2 has Correlated Miss Caching (CMC) prefetching

05:45PM EDT – Latency enchancment on L2 on account of CMC
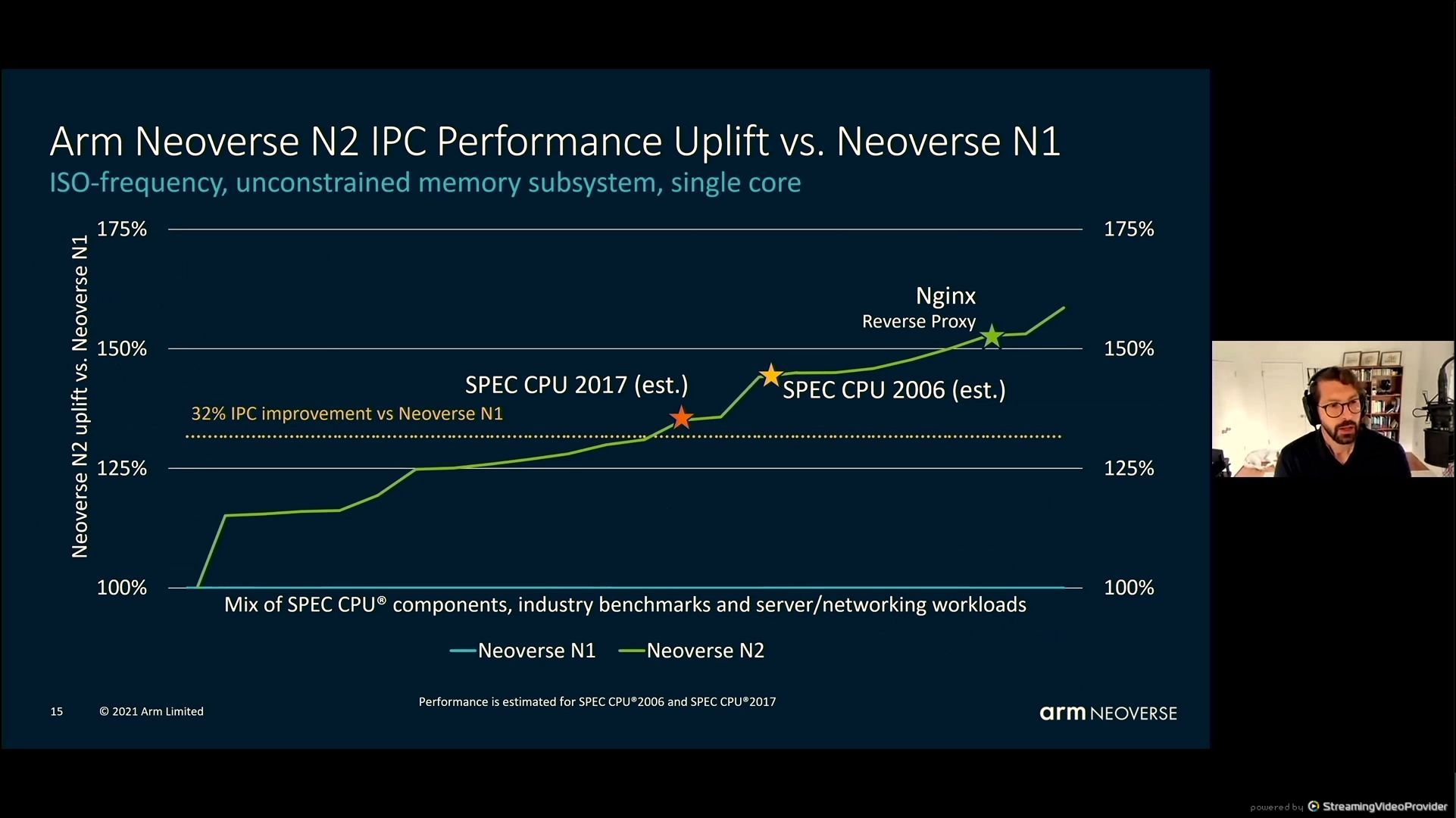
05:45PM EDT – 32% IPC enchancment at iso-frequency
05:46PM EDT – SPEC2006 was 40% talked about earlier
05:47PM EDT – Coherent Mesh Network – CMN700 – chiplets and multi-socket
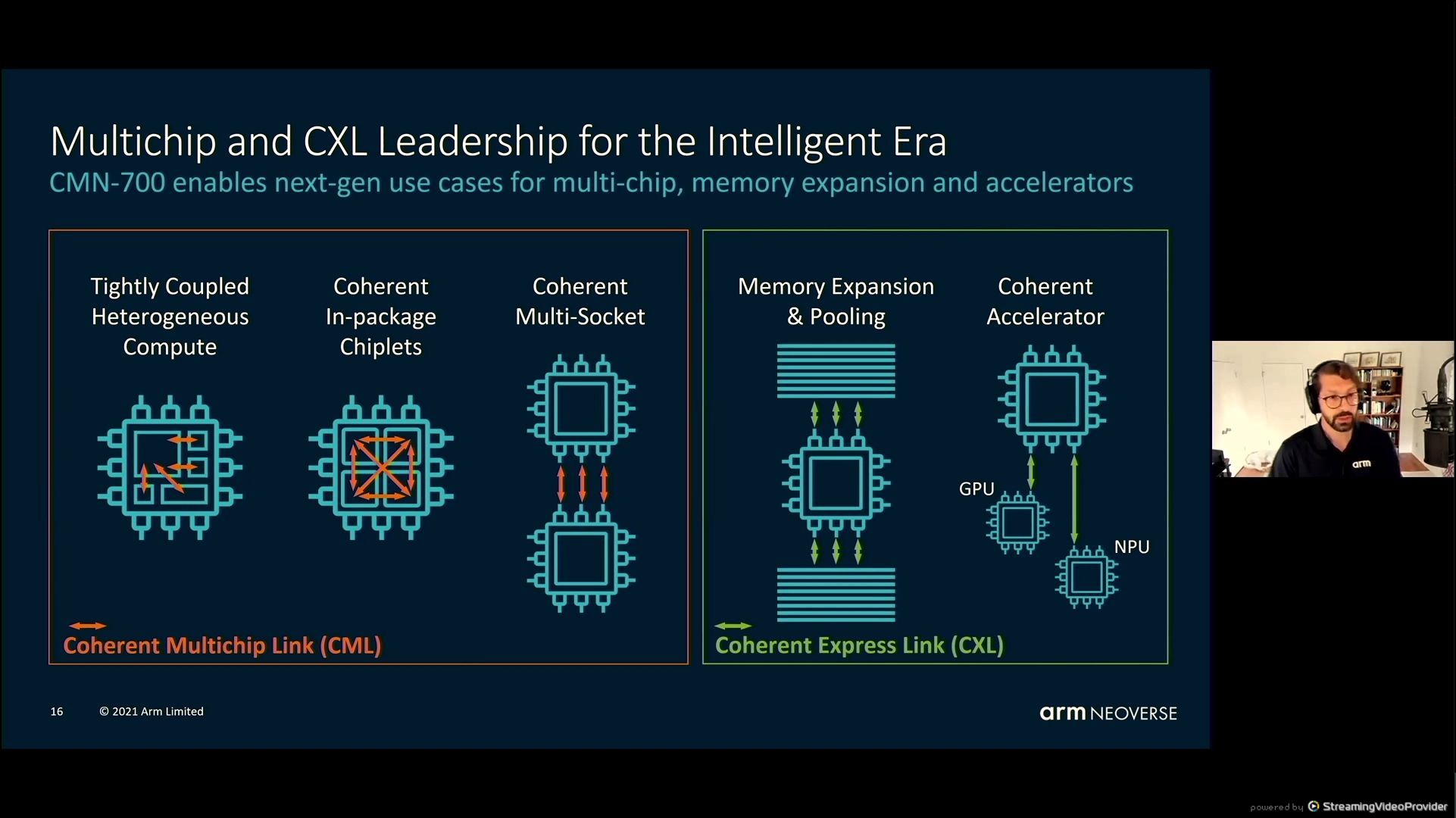
05:47PM EDT – Also CXL help

05:48PM EDT – enhancements over 600 – double mesh hyperlinks, 3x cross sectional BW
05:48PM EDT – Programmable hot-spot re-routing
05:49PM EDT – Composable Datacenter SoCs – chiplets and IO dies and tremendous dwelling dies
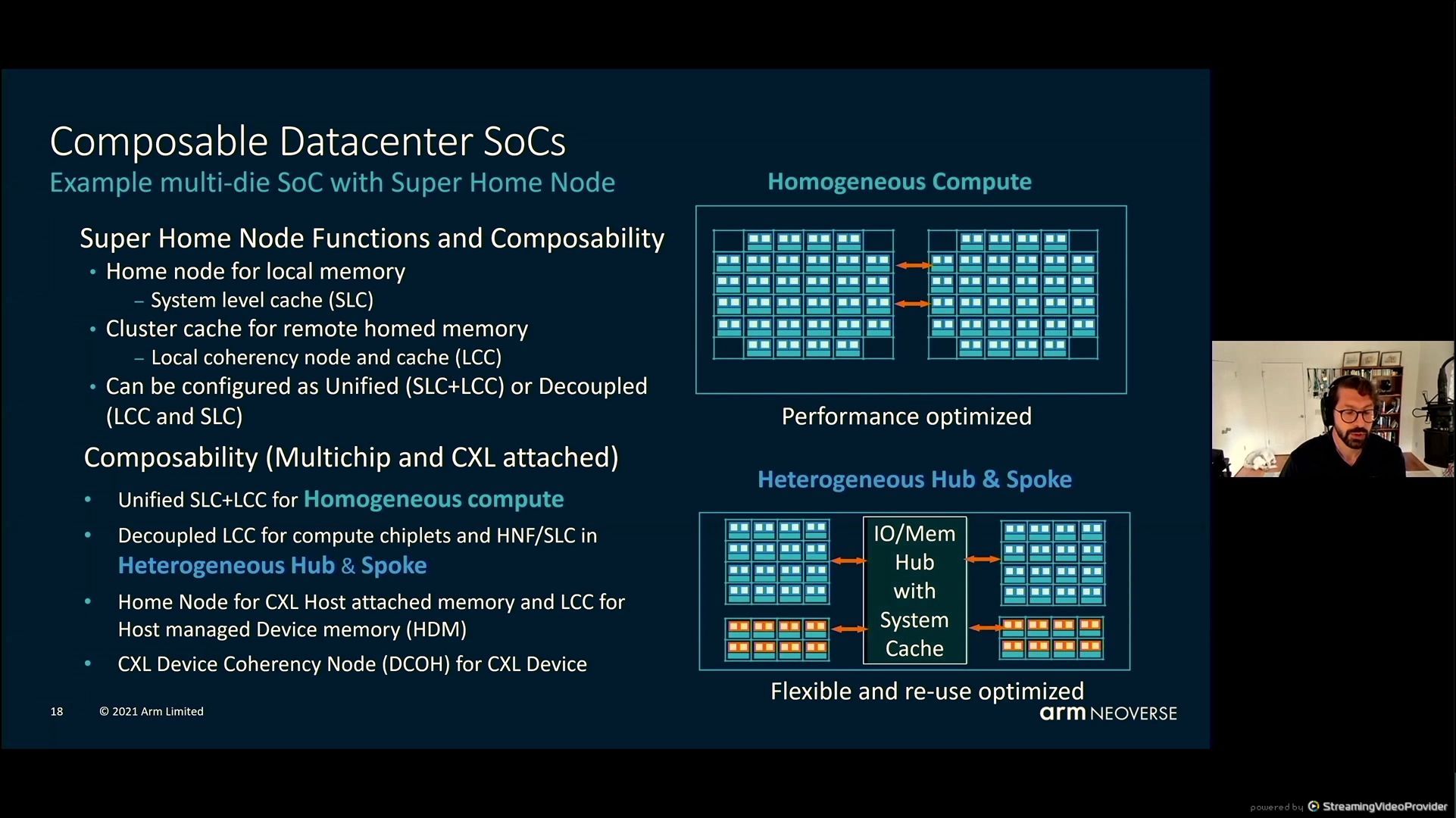

05:51PM EDT – balancing reminiscence requests
05:51PM EDT – management for capability or bandwidth
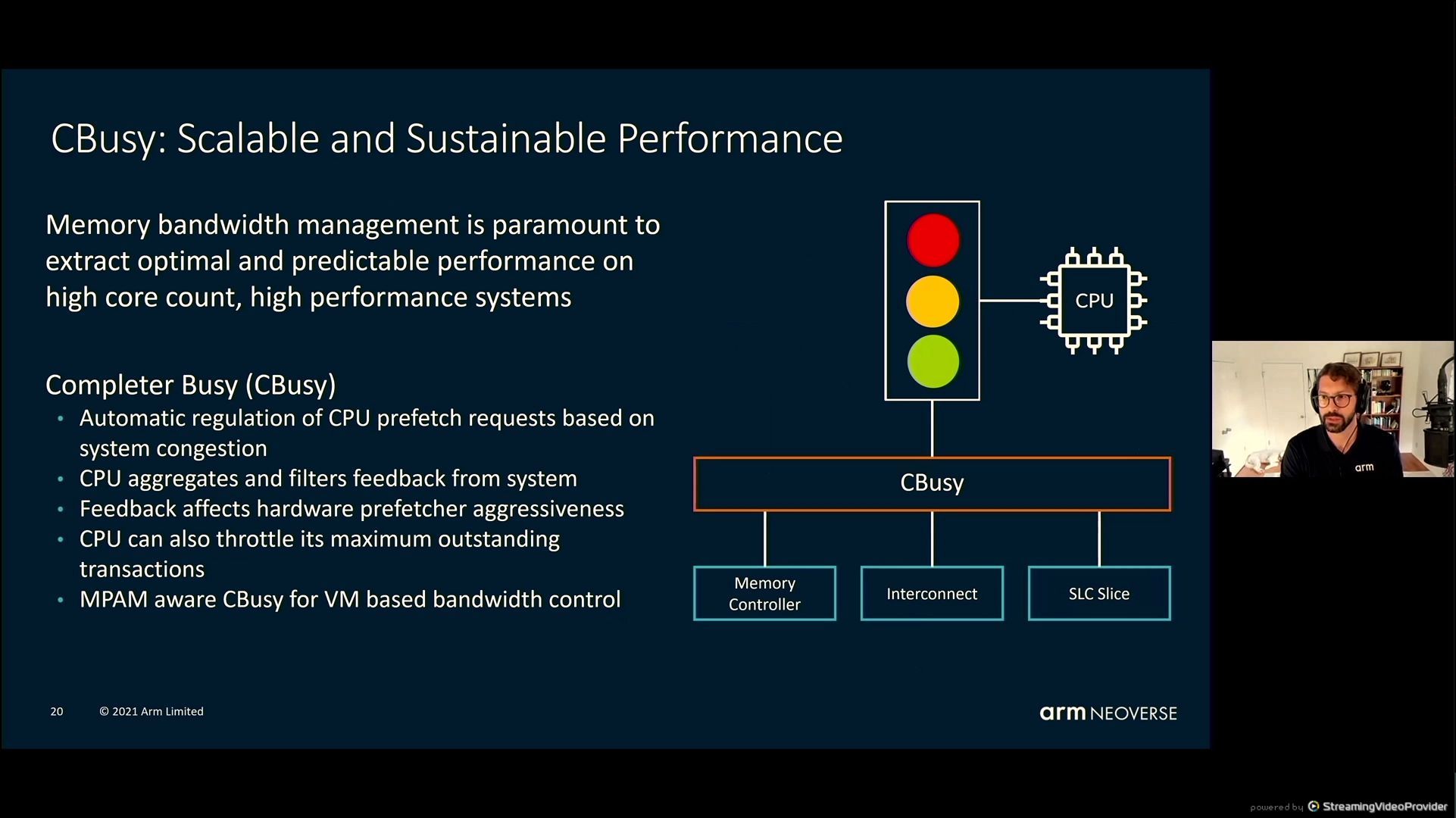
05:52PM EDT – Cbusy – throttling excellent transactions to the CPU – impacts {hardware} prefetcher aggressiveness
05:53PM EDT – Cbusy and MPAM meant to work collectively
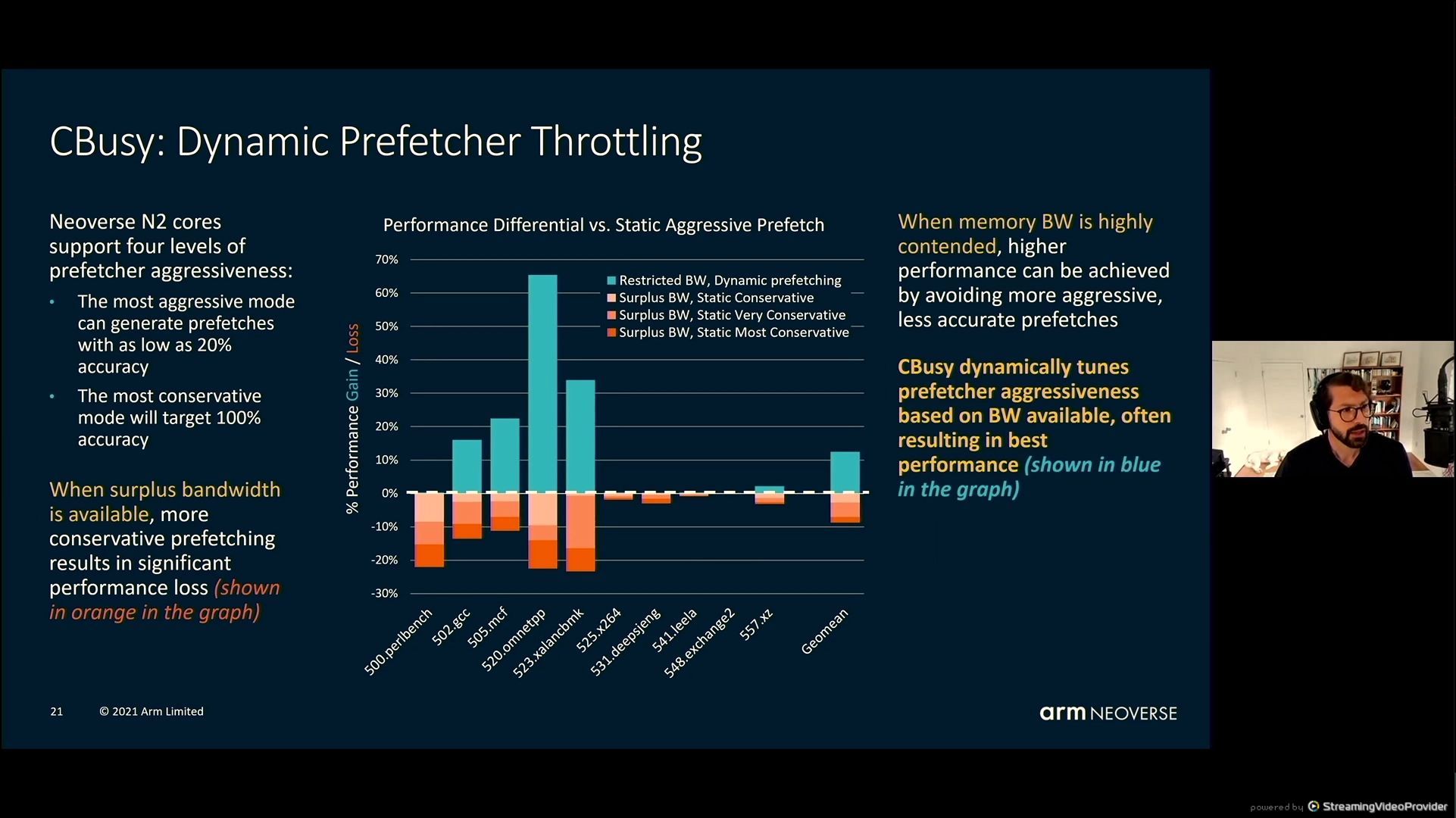
05:54PM EDT – Resulting in finest efficiency

05:56PM EDT – Compared to the market with N2
05:56PM EDT – integer efficiency solely
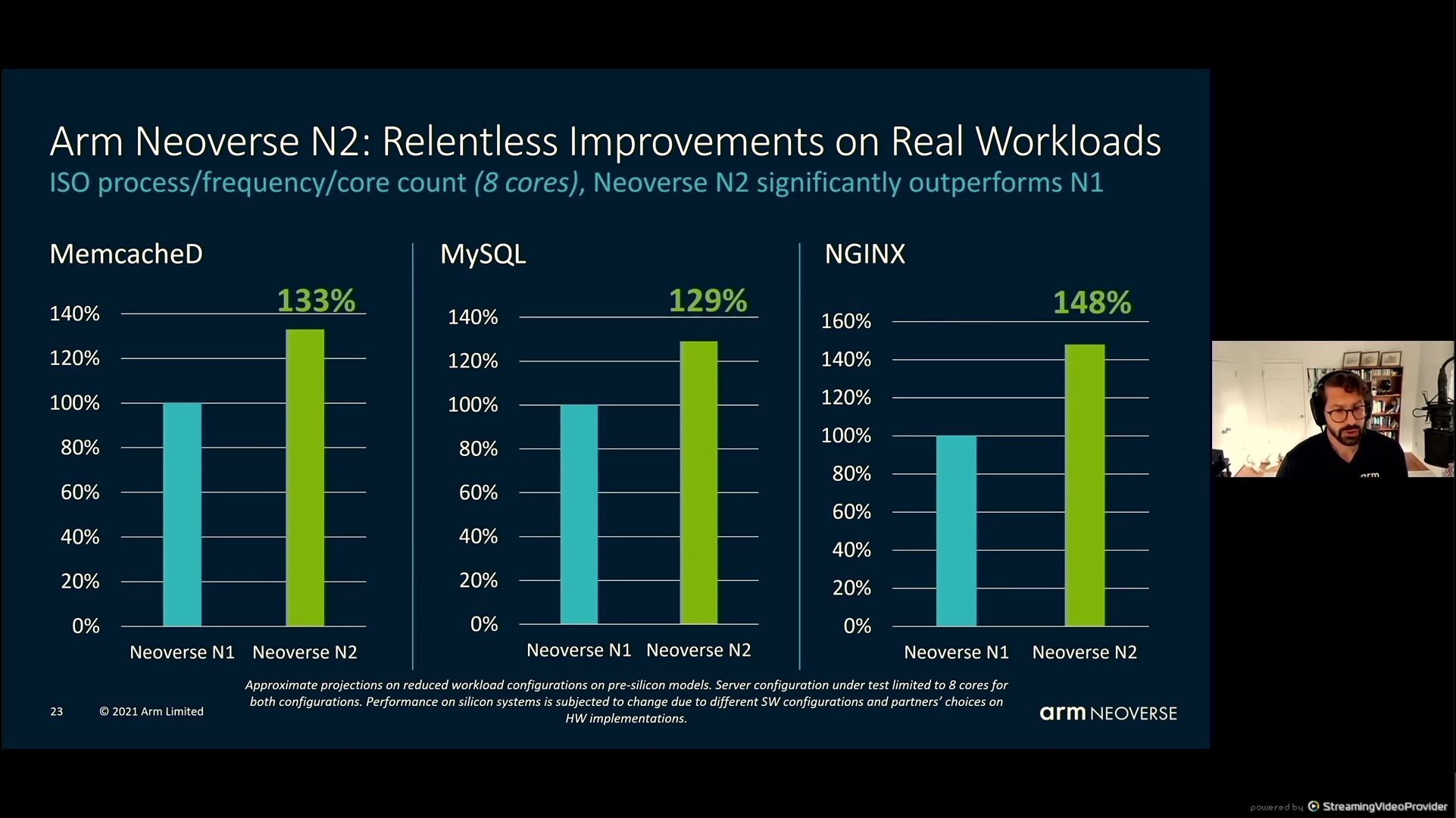
05:57PM EDT – ‘Real world workload’ numbers primarily based on pre-silicon fashions

05:58PM EDT – Up to 256 cores of N2 ought to be enjoyable
05:59PM EDT – hit the market within the subsequent few months
05:59PM EDT – Q&A
05:59PM EDT – Q: Is N1/N2 at iso-freq – what freq on slide 10? A: a variety of energy modes, quoted 2-2.5 GHz which is what clients will use
06:01PM EDT – Q: Cbusy for a heterogeneous multi-die system? A: All IPs will get the CBusy info and throttle requests,
06:03PM EDT – Q: MPAM cache partitioning? weight? A: It can do. But additionally help wonderful grain threshholds for management – you may tune primarily based on capability with out overpartitioning
06:03PM EDT – Second speak of the session – NVIDIA DPU
06:04PM EDT – Idan Burstein, co-authored NVMoF

06:04PM EDT – Architecture and platform use-cases

06:05PM EDT – Data middle goes by means of a revolution
06:05PM EDT – Fully disaggregate your server between compute, reminiscence, acceleration, storage, and software program. Requires accelerated networking and DPUs to manage all of it
06:06PM EDT – 10-20x bandwidth deployed per server requires higher networking
06:06PM EDT – a Datacenter infrastructure workload
06:08PM EDT – Moving infrastructure workloads to the CPU is a foul concept
06:08PM EDT – Need acceptable offload





