
One of the extra fascinating AI silicon initiatives over the past couple of years has been the Cerebras Wafer Scale Engine, most notably for the truth that a single chip is the dimensions of a literal wafer. Cerebras packs the WSE1 chip right into a 15U customized liquid cooled server, referred to as the CS-1, with numerous improvements concerning packaging, energy, and setup. A single CS-1 requires about 20 kW of energy peak, and prices round a pair million {dollars} (the Pittsburgh Supercomputing Center bought two final 12 months primarily based on a $5m analysis grant). Cerebras say they’ve double digit prospects and several other dozen items already within the subject, nevertheless right this moment marks a substantial milestone because the US Department of Energy now has one deployed and dealing, connected on to a supercomputer.
It is pretty straightforward to be marveled at Cerebras’ design, which includes numerous improvements and patents concerning cross-reticle connectivity, and the 400,000 AI cores within the processor are designed to resist manufacturing defects by providing spare cores all through the design that can be utilized in place. This provides every wafer an excellent yield – each chip off the manufacturing line is useable. Cerebras is a options supplier, not only a chip designer, and consequently it sells WSE1 in a self-contained 15U rack-mountable unit. The goal of the CS-1 design is that it will possibly match into any normal datacenter, you plug within the energy and the networking, and away you go.

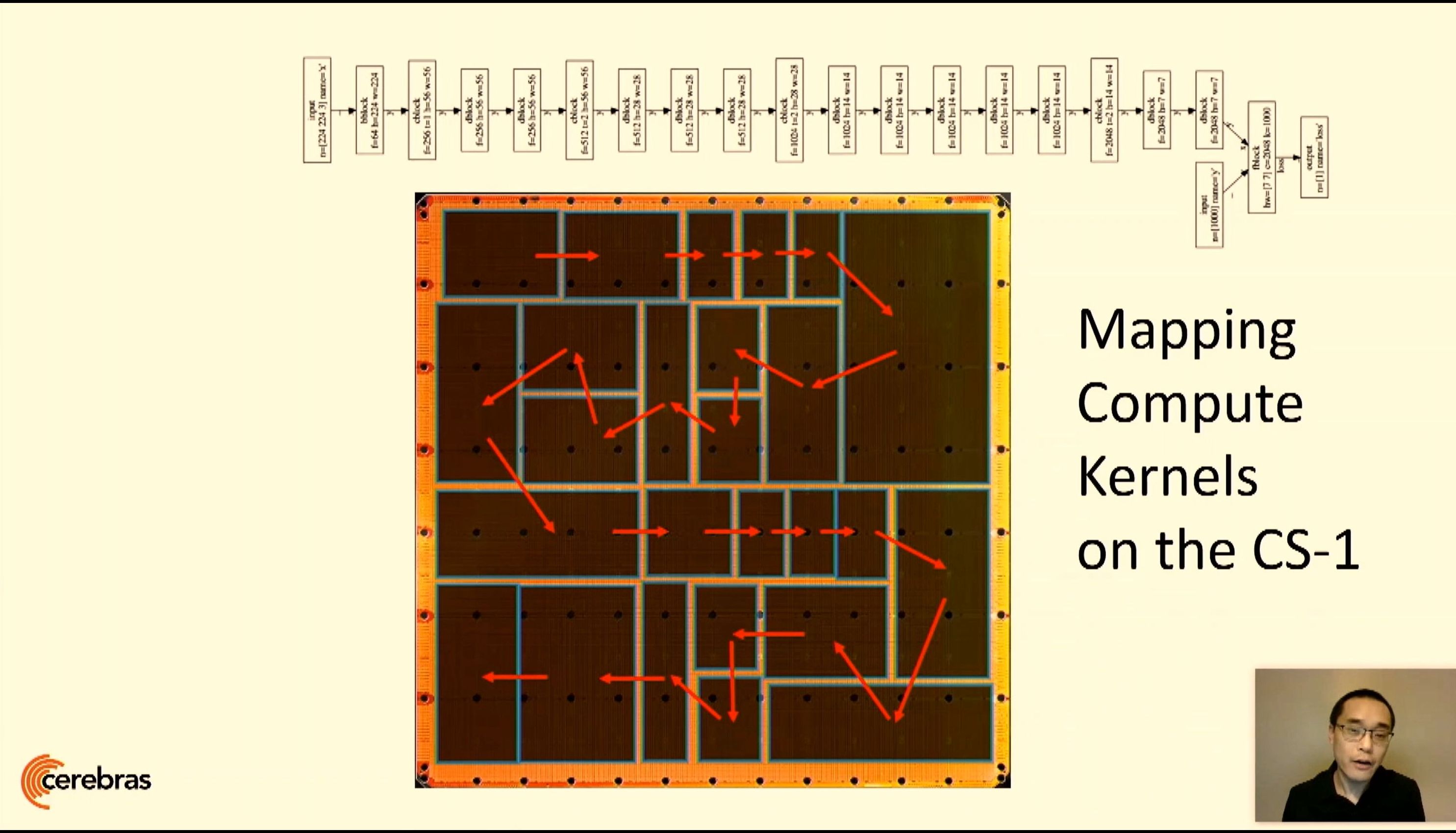
On the software program aspect of issues, Cerebras has its personal graph compiler for its chip, which accepts AI networks primarily based on TensorFlow and pyTorch, after which configures them in essentially the most optimum manner across the large chip. This 12 months at Hot Chips, the corporate went into some element about how programming on the wafer scale works, with the compiler balancing compute and on-chip sources to make use of the very best area-vs-performance tradeoffs for any given AI operate or kernel. Each kernel will be cut up in mannequin parallel or information parallel trend with the intention to generate the optimum communication sample, maximizing the efficiency and finally the on-chip use. Users also can hand-optimize kernels if required. The graph compiler can be designed to make environment friendly work of sparse networks, particularly with having such a big chip and 18 GB of onboard SRAM in addition to a full MIMD structure.
The information right this moment nevertheless is that Cerebras is saying an important CS-1 set up. It might solely be a single unit, however the Lawrence Livermore National Laboratory (LLNL), as funded by the US Department of Energy’s National Nuclear Security Administration, has bought a CS-1 unit and bolted it onto its 23 PetaFLOP ‘Lassen’ Supercomputer. The Lassen supercomputer is a 684-node Power9 + Volta + Infiniband supercomputer, rated at round 23 PetaFLOPs and at the moment sits at #14 on the TOP500 record.

The objective of including a CS-1 to Lassen is to assist speed up and offload focused AI analysis and modelling help. Lassen is primarily used for nuclear simulations, materials science, drug design, and medical evaluation. These initiatives usually contain longer-than-the-universe search areas of computational evaluation, and these initiatives are beginning to use AI coaching and inference to assist scale back the search areas and optimize the place the compute is required, decreasing wasted compute and minimizing errors. This will probably be one of many targets of the CS-1 connected to Lassen, each for coaching these search area fashions after which making use of them at a bigger scale by means of inference. This would be the first time that LLNL has added AI-specific {hardware} to its computational repertoire, and the time period getting used for attaching AI acceleration onto HPC compute is being referred to as Cognitive Simulation, or CogSim for brief.
“We want new solutions for how one can enhance…





