
The previous couple of years has seen a glut of processors enter the market with the only real goal of accelerating synthetic intelligence and machine studying workloads. Due to the several types of machine studying algorithms doable, these processors are sometimes targeted on a couple of key areas, however one factor limits all of them – how huge you can also make the processor. Two years in the past Cerebras unveiled a revolution in silicon design: a processor as huge as your head, utilizing as a lot space on a 12-inch wafer as an oblong design would permit, constructed on 16nm, targeted on each AI in addition to HPC workloads. Today the corporate is launching its second era product, constructed on TSMC 7nm, with greater than double the cores and greater than double of all the things.
Second Generation Wafer Scale Engine
The new processor from Cerebras builds on the primary by shifting to TSMC’s N7 course of. This permits the logic to scale down, in addition to to some extent the SRAMs, and now the brand new chip has 850,000 AI cores on board. Basically nearly all the things in regards to the new chip is over 2x:
| Cerebras Wafer Scale | |||
| AnandTech | Wafer Scale Engine Gen1 |
Wafer Scale Engine Gen2 |
Increase |
| AI Cores | 400,000 | 850,000 | 2.13x |
| Manufacturing | TSMC 16nm | TSMC 7nm | – |
| Launch Date | August 2019 | Q3 2021 | – |
| Die Size | 46225 mm2 | 46225 mm2 | – |
| Transistors | 1200 billion | 2600 billion | 2.17x |
| (Density) | 25.96 mTr/mm2 | 56.246 mTr/mm2 | 2.17x |
| On-board SRAM | 18 GB | 40 GB | 2.22x |
| Memory Bandwidth | 9 PB/s | 20 PB/s | 2.22x |
| Fabric Bandwidth | 100 Pb/s | 220 Pb/s | 2.22x |
| Cost | $2 million+ | arm+leg | ‽ |
As with the unique processor, generally known as the Wafer Scale Engine (WSE-1), the brand new WSE-2 options a whole lot of 1000’s of AI cores throughout a large 46225 mm2 of silicon. In that house, Cerebras has enabled 2.6 trillion transistors for 850,000 cores – by comparability, the second largest AI CPU available on the market is ~826 mm2, with 0.054 trillion transistors. Cerebras additionally cites 1000x extra onboard reminiscence, with 40 GB of SRAM, in comparison with 40 MB on the Ampere A100.
Me with Wafer Scale Gen1 – seems the identical, however with lower than half the cores.
The cores are related with a 2D Mesh with FMAC datapaths. Cerebras achieves 100% yield by designing a system through which any manufacturing defect could be bypassed – initially Cerebras had 1.5% further cores to permit for defects, however we’ve since been advised this was method an excessive amount of as TSMC’s course of is so mature. Cerebras’ objective with WSE is to supply a single platform, designed by revolutionary patents, that allowed for larger processors helpful in AI calculations however has additionally been prolonged right into a wider array of HPC workloads.
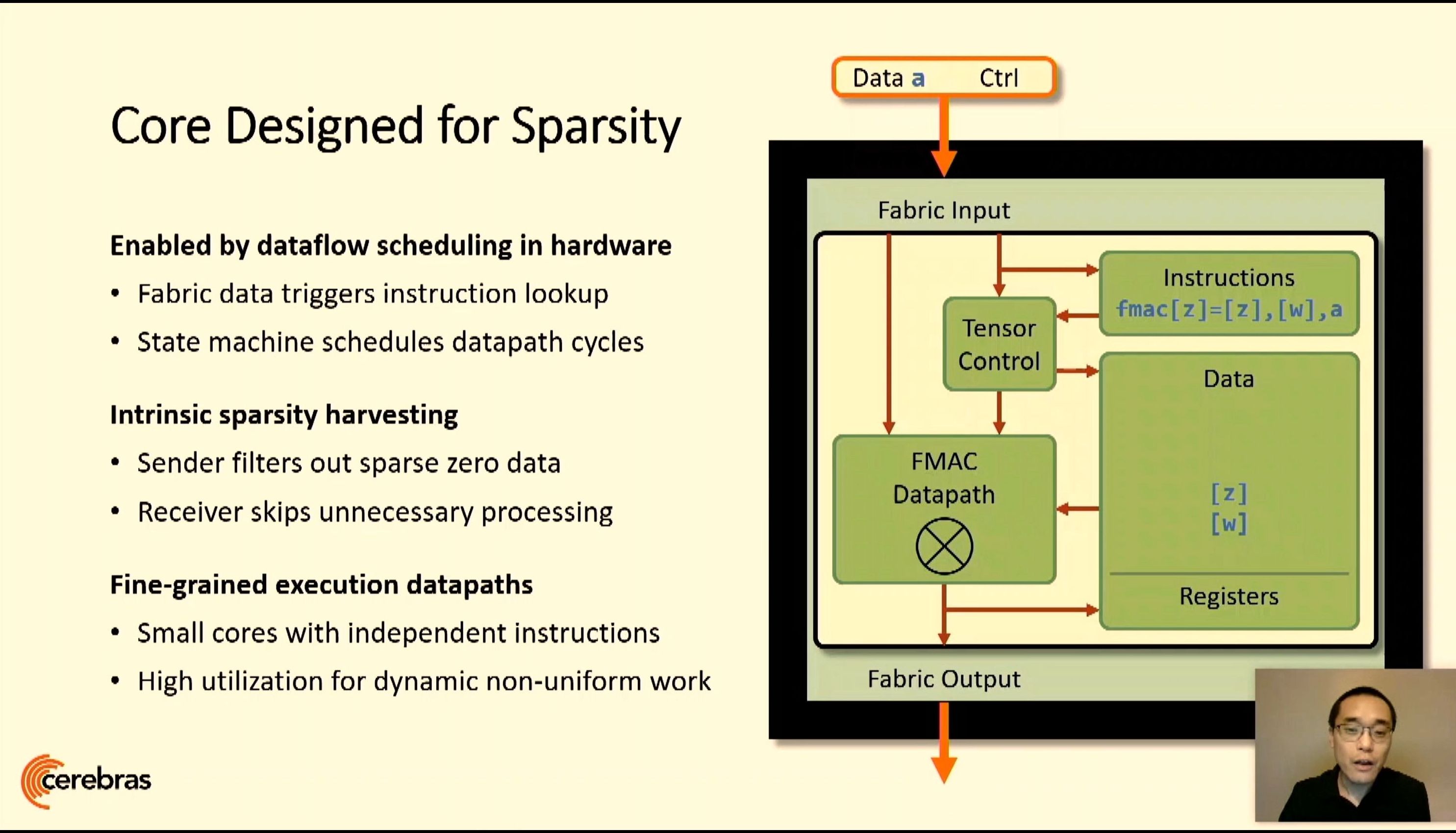
Building on First Gen WSE
A key to the design is the customized graph compiler, that takes pyTorch or TensorFlow and maps every layer to a bodily a part of the chip, permitting for asynchronous compute as the information flows by. Having such a big processor means the information by no means has to go off-die and wait in reminiscence, losing energy, and may regularly be moved onto the subsequent stage of the calculation in a pipelined style. The compiler and processor are additionally designed with sparsity in thoughts, permitting excessive utilization no matter batch measurement, or can allow parameter search algorithms to run concurrently.

For Cerebras’ first era WSE is offered as a whole system known as CS-1, and the corporate has a number of dozen clients with deployed programs up and working, together with various analysis laboratories, pharmaceutical firms, biotechnology analysis, navy, and the oil and fuel industries. Lawrence Livermore has a CS-1 paired to its 23 PFLOP ‘Lassen’ Supercomputer. Pittsburgh Supercomputer Center bought two programs…




