
In their own side event this week, AMD invited select members of the press and analysts to come and discuss the next layer of Zen details. In this piece, we’re discussing the microarchitecture announcements that were made, as well as a look to see how this compares to previous generations of AMD core designs.
Prediction, Decode, Queues and Execution
First up, let’s dive right into the block diagram as shown:
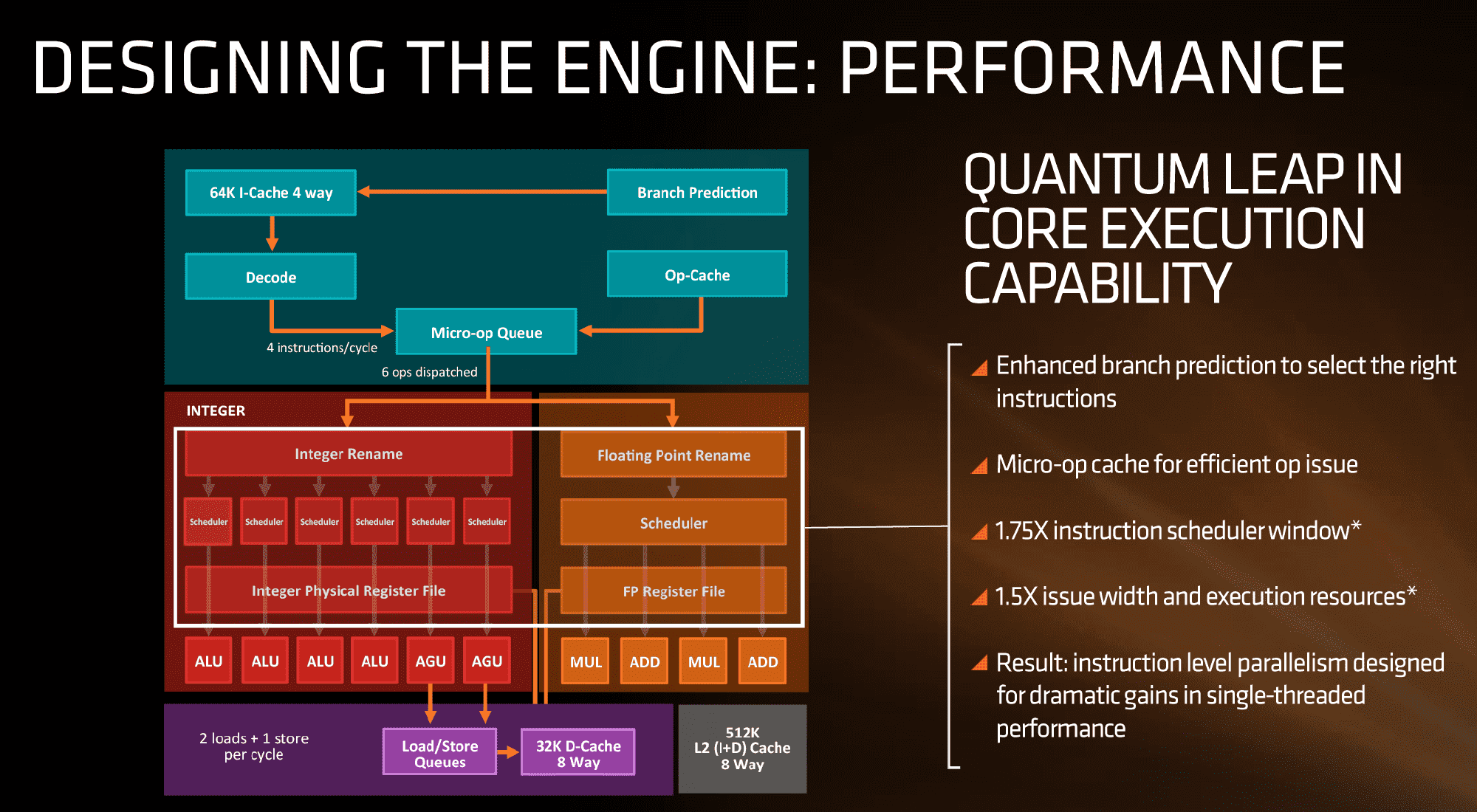
If we focus purely on the left to start, we can see most of the high-level microarchitecture details including basic caches, the new inclusion of an op-cache, some details about decoders and dispatch, scheduler arrangements, execution ports and load/store arrangements. A number of slides later in the presentation talk about cache bandwidth.
Firstly, one of the bigger deviations from previous AMD microarchitecture designs is the presence of a micro-op cache (it might be worth noting that these slides sometimes say op when it means micro-op, creating a little confusion). AMD’s Bulldozer design did not have an operation cache, requiring it to fetch details from other caches to implement frequently used micro-ops. Intel has been implementing a similar arrangement for several generations to great effect (some put it as a major stepping stone for Conroe), so to see one here is quite promising for AMD. We weren’t told the scale or extent of this buffer, and AMD will perhaps give that information in due course.
Aside from the as-expected ‘branch predictor enhancements’, which are as vague as they sound, AMD has not disclosed the decoder arrangements in Zen at this time, but has listed that they can decode four instructions per cycle to feed into the operations queue. This queue, with the help of the op-cache, can deliver 6 ops/cycle to the schedulers. The reasons behind the queue being able to dispatch more per cycle is if the decoder can supply an instruction which then falls into two micro-ops (which makes the instruction vs micro-op definitions even muddier). Nevertheless, this micro-op queue helps feed the separate integer and floating point segments of the CPU. Unlike Intel who uses a combined scheduler for INT/FP, AMD’s diagram suggests that they will remain separate with their own schedulers at this time.
The INT side of the core will funnel the ALU operations as well as the AGU/load and store ops. The load/store units can perform 2 16-Byte loads and one 16-Byte store per cycle, making use of the 32 KB 8-way set associative write-back L1 Data cache. AMD has explicitly made this a write back cache rather than the write through cache we saw in Bulldozer that was a source of a lot of idle time in particular code paths. AMD is also stating that the load/stores will have lower latency within the caches, but has not explained to what extent they have improved.
The FP side of the core will afford two multiply ports and two ADD ports, which should allow for two joined FMAC operations or one 256-bit AVX per cycle. The combination of the INT and FP segments means that AMD is going for a wide core and looking to exploit a significant amount of instruction level parallelism. How much it will be able to depends on the caches and the reorder buffers – no real data on the buffers has been given at this time, except that the cores will have a +75% bigger instruction scheduler window for ordering operations and a +50% wider issue width for potential throughput. The wider cores, all other things being sufficient, will also allow AMD’s implementation of simultaneous multithreading to potentially take advantage of multiple threads with a linear and naturally low IPC.
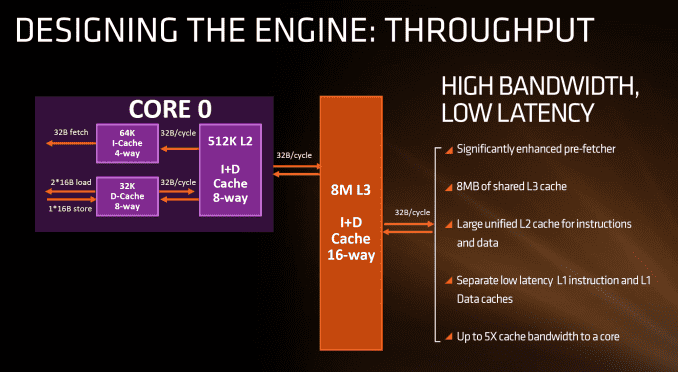
The cache hierarchy is a significant deviation from recent previous AMD designs, and most likely to its advantage. The L1 data cache is both double in size and increased in associativity compared to Bulldozer, as well as being write-back rather than write-through. It also uses an asymmetric load/store implementation, identifying that loads happen more often than stores in the critical paths of most work flows. The instruction cache is no longer shared between two cores as well as doubling in associativity, which should decrease the proportion of cache misses. AMD states that both the L1-D and L1-I are low latency, with details to come.
The L2 cache sits at half a megabyte per core with 8-way associativity, which is double that of Intel’s Skylake which has 256 KB/core and is only 4-way. On the other hand, Intel’s L3/LLC on their high-end Skylake SKUs is at 2 MB/core or 8 MB/CPU, whereas Zen will feature 1 MB/core and both are at 16-way associativity.
Edit 7:18am: Actually, the slide above is being slightly evasive in its description. It doesn’t say how many cores the L3 cache is stretched over, or if there is a common LLC between all cores in the chip. However, we have recieved information from a source (which can’t be confirmed via public AMD documents) that states that Zen will feature two sets of 8MB L3 cache between two groups of four cores each, giving 16 MB of L3 total. This would means 2 MB/core, but it also implies that there is no last-level unified cache in silicon across all cores, which Intel has. The reasons behind something like this is typically to do with modularity, and being able to scale a core design from low core counts to high core counts. But it would still leave a Zen core with the same L3 cache per core as Intel.
| Cache Levels | ||||
| Bulldozer FX-8150 |
Zen | Broadwell-E i7-6950X |
Skylake i7-6700K |
|
| L1 Instruction | 64 KB 2-way per module |
64 KB 4-way | 32 KB 8-way | 32 KB 8-way |
| L1 Data | 16 KB 4-way Write Through |
32 KB 8-way Write Back |
32 KB 8-way Write-Back |
32 KB 8-way Write-Back |
| L2 | 2 MB 16-way per module |
512 KB 8-way | 256 KB 8-way | 256 KB 4-way |
| L3 | 1 MB/core 64-way |
1 or 2 MB/core ? 16-way |
2.5 MB/core 16/20-way |
2 MB/core 16-way |
What this means, between the L2 and the L3, is that AMD is putting more lower level cache nearer the core than Intel, and as it is low level it becomes separate to each core which can potentially improve single thread performance. The downside of bigger and lower (but separate) caches is how each of the cores will perform snoop in each other’s large caches to ensure clean data is being passed around and that old data in L3 is not out-of-date. AMD’s big headline number overall is that Zen will offer up to 5x cache bandwidth to a core over previous designs.
When AMD launched Carrizo and Bristol Ridge for notebooks, one of the big stories was how AMD had implemented a number of techniques to improve power consumption and subsequently increase efficiency. A number of those lessons have come through with Zen, as well as a few new aspects in play due to the lithography.
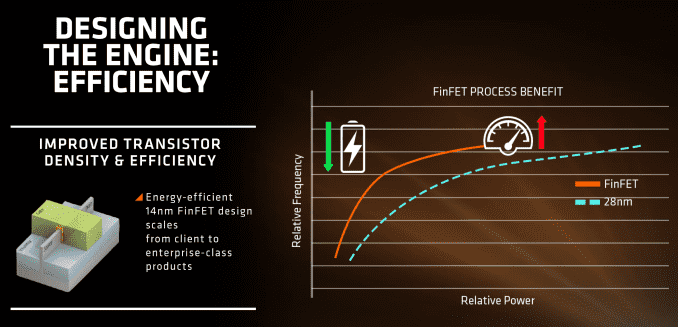
First up is the FinFET effect. Regular readers of AnandTech and those that follow the industry will already be bored to death with FinFET, but the design allows for a lower power version of a transistor at a given frequency. Now of course everyone using FinFET can have a different implementation which gives specific power/performance characteristics, but Zen on the 14nm FinFET process at Global Foundries is already a known quantity with AMD’s Polaris GPUs which are built similarly. The combination of FinFET with the fact that AMD confirmed that they will be using the density-optimised version of 14nm FinFET (which will allow for smaller die sizes and more reasonable efficiency points) also contributes to a shift of either higher performance at the same power or the same performance at lower power.

AMD stated in the brief that power consumption and efficiency was constantly drilled into the engineers, and as explained in previous briefings, there ends up being a tradeoff between performance and efficiency about what can be done for a number of elements of the core (e.g. 1% performance might cost 2% efficiency). For Zen, the micro-op cache will save power by not having to go further out to get instruction data, improved prefetch and a couple of other features such as move elimination will also reduce the work, but AMD also states that cores will be aggressively clock gated to improve efficiency.
We saw with AMD’s 7th Gen APUs that power gating was also a target with that design, especially when remaining at the best efficiency point (given specific performance) is usually the best policy. The way the diagram above is laid out would seem to suggest that different parts of the core could independently be clock gated depending on use (e.g. decode vs FP ports), although we were not able to confirm if this is the case. It also relies on having very quick (1-2 cycle) clock gating implementations, and note that clock gating is different to power-gating, which is harder to implement.
On Zen, each core will be able to support two threads in what is called ‘simulatenous multi-threading’. Intel has supported their version of SMT for a number of years, and other CPU manufacturers like IBM support up to 8 threads per core on their POWER8 platform designs. Building a core to be able to use multiple threads can be tough, as it requires a lot of resources to make sure that the threads do not block each other by consuming all the cache and buffers in play. But AMD will equip Zen with SMT which means we will see 8C/16T parts hitting the market.
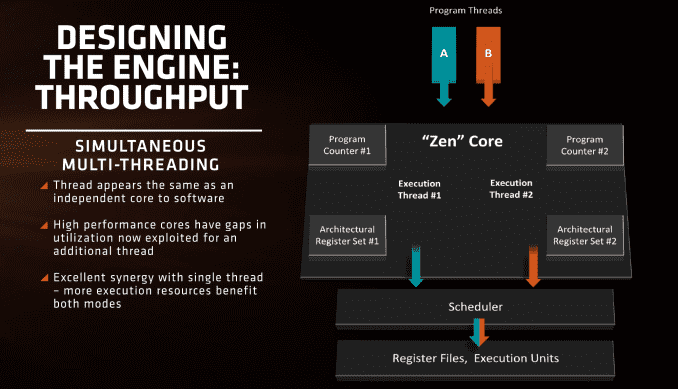
Unlike Bulldozer, where having a shared FP unit between two threads was an issue for floating point performance, Zen’s design is more akin to Intel’s in that each thread will appear as an independent core and there is not that resource limitation that BD had. With sufficient resources, SMT will allow the core instructions per clock to improve, however it will be interesting to see what workloads will benefit and which ones will not.
Timeframe and Availability
At the…





