
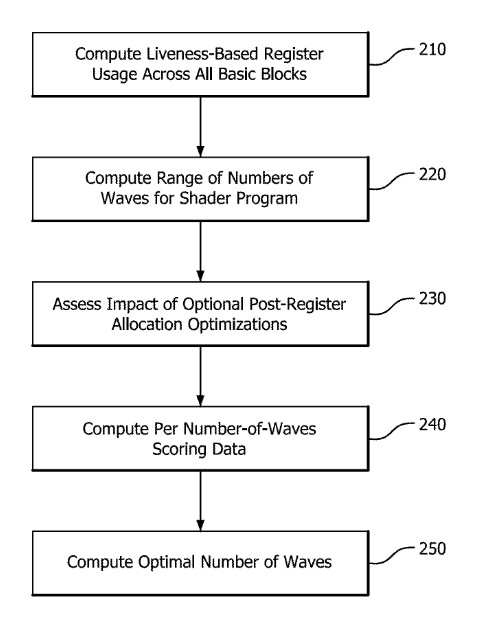
On June 13th, AMD revealed a brand new methodology for instruction scheduling of shader applications for a GPU. The methodology operates on fastened variety of registers. It works in 5 phases:
- Compute liveness-based register utilization throughout all fundamental blocks
- Computer vary of numbers of waves for shader program
- Assess the impression of obtainable post-register allocation optimizations
- Compute the scoring knowledge primarily based on variety of waves of the plurality of registers
- Compute optimum variety of waves
It is vital to notice that the “liveness” of registers is most likely a reference to register utilization, whereas the time period “wave” refers back to the machine states, like for instance EOP (End Of Pipe) and DRAW which attracts the shader. There are after all many extra states however these are simply few examples from AMD’s “GPU Open” documentation. The new methodology is meant to carry further efficiency enhancements and scale back latency by making knowledge (machine states on this case) like a wave that’s saved in a register.
You can discover out extra about it right here.





